- 近期网站停站换新具体说明
- 按以上说明时间,延期一周至网站时间26-27左右。具体实施前两天会在此提前通知具体实施时间
主题:【半原创】Flickr 网站架构研究(1) -- 西电鲁丁
家园 【原创】Flickr 网站架构研究(4) 海量文件系统设计的考虑因素在具体讨论Flickr的文件存储系统设计之前,我们这里先来简要的介绍一下海量文件系统设计时需要考虑的一些基本因素:
1。数据库还是文件系统?
文件存在哪儿?这个可能是大家问的第一个也可能是最多的问题了,一般来说,业界公认的方法是数据库存放元数据和文件路径(可以是绝对路径,也可以是相对路径+卷路径),而实际文件则存放在文件系统,大多数大型图片网站如Flickr和企业内容管理(ECM)软件厂商都采用这种方法(或者同时支持数据库和文件系统两种方式),原因在于
1)数据库系统在增大到一定规模后,比如上TB级后管理维护和效率都是一个很大的挑战(升级硬件是一个办法,如果有钱
 ),例如Flickr现今已有超过6PB的照片文件,全部以BLOB方式存入数据库几乎不可能。当然也有例外,比如微软的Sharepoint 2007就是全部文件都存入SQL SERVER数据库的,微软的建议是一个Sharepoint library的文件数不要超过5百万,如果超过的话则可以采用scale-out方式。记得几年前在MSDN上看过一篇文章,介绍微软采用了几百台sharepoint 2001 server来搭建自己的一个内部知识库网站。采用数据库的方式,虽然有些限制,但也不是绝对不可以。
),例如Flickr现今已有超过6PB的照片文件,全部以BLOB方式存入数据库几乎不可能。当然也有例外,比如微软的Sharepoint 2007就是全部文件都存入SQL SERVER数据库的,微软的建议是一个Sharepoint library的文件数不要超过5百万,如果超过的话则可以采用scale-out方式。记得几年前在MSDN上看过一篇文章,介绍微软采用了几百台sharepoint 2001 server来搭建自己的一个内部知识库网站。采用数据库的方式,虽然有些限制,但也不是绝对不可以。2)以BLOB方式存储文件,当文件大小超过一定阀值后数据库的读写响应将急剧下降。下面的图摘自某著名ECM厂商的研究报告,这张是比较不同大小的文件存入数据库和文件系统的响应时间的(蓝线是数据库,红线是文件系统)
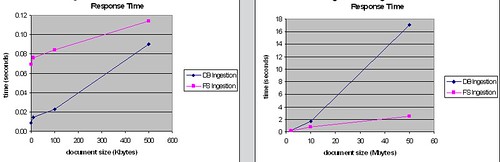 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改这张是比较从数据库和文件系统读取不同大小的文件的响应时间的
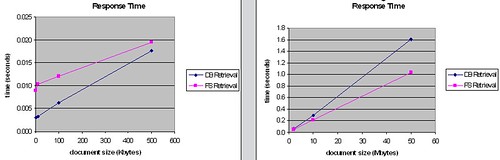 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改从中可以看出,这个阀值是大约500KB-1MB左右,小于这个阀值,数据库的读写效率要高于文件系统,而大于这个阀值,文件系统的优势就体现出来了。不同的测试条件和软硬件下这个阀值会有所不同,但趋势应该是一致的。
采用文件系统方式的一个主要缺点是难以保证元数据和文件的一致性(在数据库方式下可以通过事务的方式来保证这一点),所以需要定期运行特定的程序进行一致性检查。
2。通用文件系统的问题。
早期的通用文件系统的设计初始并没有考虑到海量文件的存取,主要的表现为当一个目录下的文件数超过一定时,访问这个目录下文件的时间将大大增加,例如在NT4.0时代,这个值是大约5000,后来的Windows 2000/2003和Unix/Linux要好的多,不过这个限制依然存在。早期的NTFS或基于BSD Fast Filesystem的Unix/Linux文件系统,对于目录/inode的设计是采用采用简单的顺序查找的方式来定位目录下的文件,虽然稍后一些的文件系统设计增加了cache来提高效率,不过还是难以应付一个目录下有大量文件的情况;较为现代的JFS, Reiserfs, XFS, HFS和较新的NTFS版本对于目录结构采用了B-Tree的设计,因而大大提高了效率,但存在的问题是一旦较高层次的父节点数据损害,则可能会丢失所有的子节点。Linux 2.6的ext3和ext4文件系统有鉴于此,采用了一种相对简单但较高效和安全的HTree(Hash Tree)的方法,即可以利用hash table来提高访问效率,又保留了原来的顺序查找的结构,这样一旦hash table的数据丢失也依然可以通过顺序查找的结构来访问和恢复。
尽管效率有所提高,还是不建议在一个目录和一个文件系统下放置太多的文件。对于NTFS下的目录,个人理解这个临界点大约是30万,微软建议,当一个NTFS目录下文件数超过30万时,关掉短文件名(即DOS兼容模式的8.3)的生成(可通过注册表或fsutil behavior set disable8dot3 1命令)。对于Linux/Unix的目录以及单个文件系统,没有看到过权威的数据。(个人建议不要超过2级目录,总文件数不超过1亿吧。)一个现实的例子就是Youtube.com,Youtube最初采用几台Linux服务器存放所有视频的截屏(一个视频大约4-5个截屏),后来由于目录下文件太多以至大大影响了性能,在被Google收购之后,移植到了Google的BigTable,才最终解决了问题。
对于类似的照片网站,另一个建议是关掉文件系统的last access time的读写。缺省情况下,每一次文件访问,文件系统都会更新文件的last access time,这样会造成大量的写操作。对于这类网站,其实并不关心每一个文件的最后访问时间。对于Unix/Linux,可以通过在mount时选用noatime参数来关掉last access time;对于NTFS,可通过注册表或fsutil behavior set disablelastaccess 1的命令。但要注意的是,一些备份软件/策略可能根据这个时间来进行备份,在关掉这个选项之前需要仔细考虑替代方案。
除了通用文件系统之外,也有一些基于通用文件系统加以改造或是干脆重起炉灶重写的分布式文件系统比如Google File system(GFS),IBM 的General Parallel File System (GPFS),和著名的memcached师出同门的MogileFS,以及Facebook新近研发成功的Haystack系统等,这些系统在一定程度上克服了通用文件系统的限制,但在成熟度,开放性和技术支持上还有待观察。
3。存储设备的选择。
存储设备的选择是个见仁见智的事情,大厂商的存储设备通常有一些独特的功能,比如snapshot,replication,WORM-Like Disk(类似CD-R以满足法律法规的要求)等,缺点当然就是价格昂贵;而通用硬件价格便宜,采购灵活,缺点是应用软件需要实现更多的功能,而且维护成本较高,可能需要几百台服务器来达到同样的存储容量。对比两大网站:Flickr最初采用了通用的硬件而后似乎是基于维护的原因而转向NetApp;而Facebook在砸出大把大把的银子购进NetApp后最近由于性能和TCO的原因开始考虑通用硬件。重要的在于软件和应用系统的设计要不依赖于特定厂商的产品和功能,这样在需要的时候可以有更多的选择,虽然数据移植是一件很痛苦的事。
家园 深入浅出,写得真好,一个小疑问。 写得真好。吹捧的话不多说了,直接开始拍砖,
一个现实的例子就是Youtube.com,Youtube最初采用几台Linux服务器存放所有视频的截屏(一个视频大约4-5个截屏),后来由于目录下文件太多以至大大影响了性能,在被Google收购之后,移植到了Google的BigTable,才最终解决了问题。YouTube是把视频存储在BigTable里吗?BigTable是数据库,而不是文件系统。Google的文件系统是GFS。按前面的逻辑讲,似乎YouTube的视频文件应该存放在GFS,而把元数据以及文件路径放在BigTable数据库里。这样的理解是否正确?
另外,
1. 有没有关于YouTube的架构设计的文章?
2. 有没有关于Twitter架构设计的文章?把Twitter的架构与Flickr的比较一下,应该很有启发。因为这是两类不同性质的大型网站。Flickr是一站式,而Twitter本质上是离散的。
3. 翻阅了一下“Building Scalable Web Sites”,该书作者就是Flickr的架构师,Cal Henderson。但是感觉不是很好,内容庞杂,而没有突出Large scale的挑战与解决办法。
但是发现[URL=http://www.iamcal.com/talks/
]Cal Henderson的个人网站[/URL]上有很多内容。那几篇文章内容比较翔实,可否推荐一下,共同阅读,相互切磋,共同提高。
多谢好文!
家园 嗯,欢迎拍砖。 1. YouTube是把"视频的截屏",thumbnails存储在BigTable里,视频本身应该还是在文件系统里。关于GFS和bigtable本身,大概看过一点(暂时没有时间细看),GFS适合于100MB以上的大文件,而bigtable是基于GFS之上的。关于youtube的架构,参见http://highscalability.com/youtube-architecture,YouTube的视频文件的元数据可能还是在MYSQL数据库.
2。上面这个网站上也有关于twitter的文章 http://highscalability.com/scaling-twitter-making-twitter-10000-percent-faster
这个网站和西西河一样,是我每天必看的。

3. Cal Henderson这本书精华在第9章,不过其他章节也不要错过,一些细节很分散,我先后看了N遍。有些内容比较含糊,要和他个人网站上的文章和其他人的文章结合着看。我几乎把他所有的文章都看过了,如果注重scalability的话,可以重点看下面这两篇
16/09/2008 Web 2.0 Expo NYC Scalable Web Architectures: Common Patterns and Approaches
16/04/2007 Web 2.0 Expo, San Francisco Beyond the File System: Designing Large-Scale File Storage and Serving
家园 关于MemCache与Slave的比较 1.
Flickr为中央数据库配置了Memcached作为数据库缓存,接下来的问题是,为什么用Memcached?为什么Shard不需要Memcached?Memcached和Master,Slave的关系怎样?增加一个问题,从第一篇的图中看,Central DB同Shard一样,也有Master和Slave的配合。所以问题是,既然Central DB已经有了Slave,负责“读”,为什么还另外需要MemCached?
2.
"Write Through Cache"就是将所有的数据库”写“操作都先写入”Cache",然后由Cache统一去更新数据库的各个Node,“Write Through Cache"维护每一个Node的更新状态,当有读请求时,即将请求转向状态为”已同步“的Node,这样即避免了复制滞后和Memcached的同步问题,但缺点是其实现极为复杂这里所说的“Cache”,是不是指MemCached?如果是这样的话,任何对Central DB的更改,先要放到MemCached里去,然后再push到Central DB?
这样颠倒主次关系的做法,是不是很容易make troubles?
家园 1。这个原因我已经写了 Memcached作为数据库缓存的作用主要在于减轻甚至消除高负载数据库情况下频繁读取所带来的Disk I/O瓶颈,相对于数据库自身的缓存来说,具有以下优点:1)Memecached的缓存是分布式的,而数据库的缓存只限于本机;2)Memcached 缓存的是对象,可以是经过复杂运算和查询的最终结果,并且不限于数据,可以是任何小于1MB的对象,比如html文件等;而数据库缓存是以"row"为单位的,一旦"row"中的任何数据更新,整个“row"将进行可能是对应用来说不必要的更新;3)Memcached的存取是轻量的,而数据库的则相对较重,在低负载的情况下,一对一的比较,Memcached的性能未必能超过数据库,而在高负载的情况下则优势明显。一般来说内存访问是要快过disk的;Memcached更多的是扩展了数据库的”读“操作,这一点上它和Slave的作用有重叠事实上,网上关于应用memcached还是Slave,一直是有争议的。一个更激进的想法是所谓的"内存数据库",即所有数据都放入内存,数据库只是作为persist store, 参见http://natishalom.typepad.com/nati_shaloms_blog/2008/03/scaling-out-mys.html
2。 这个Cal Henderson自己也承认是很麻烦,是不是一定要这样做,有没有更好的办法,也许只有身在其中才知道。
这个cache根据我的理解是memcached,不过不敢肯定。
家园 我的问题应该这样表述 既然MemCached有什么多好处,尤其是对于“读”来说,这些好处更明显。那么为什么Central DB还需要Slave?
增加了Slave,对于“读”来说,看不出有太多好处,但是对于“写”来说,增加了同步的负担。
或许,是因为历史原因?也就是说,Flickr还没有来得及完全改造好?
家园 不完全是Flickr网站一家的问题 我想除了历史原因,Slave存在的理由还在于
memcached只是简单的key-value pair,不能执行sql语句,所以不可能把整个数据库都放到memcached里,即memcached不能替代slave的功能,而且没有slave,memcached就成了无源之水;
没有slave而把全部读压力都放到master是不可行的,如文章所述一般来说master最多有两个,超过了会有其他的问题;
所以对于大型网站来说,找到这个memcached和slave的平衡点很重要。
家园 据我粗浅的理解,shard就是把数据库横着剖分开 每个shard上的数据库结构看起来都差不多,shard A上面如果有某些表,表里存着一些客户的某些类型的数据(评论啦,照片的metadata啦等等),那么shard B上也是这么一套,只不过是针对另一些客户。文章中也说“Shard只适用于不需要join操作的表”,也就是说各客户之间的交互应该是很少的。如果是办一个用户之间交互很多的,比如Facebook这样的网站,这个架构就完全不适合了。这时候可能要把数据库纵向剖开,关于论坛的数据库在一个服务器上,在线聊天的又在另一个上……
家园 shard的问题 同意荷包兄的意见,shard可以按行切,也可以按列切。
按行切的麻烦在于join operation会很麻烦。
按列切,join的事情好办些,但是读某个用户的所有数据时,速度会放慢。
家园 每个shard上的数据库结构应该是基本一样的, 客户之间的交互主要靠数据冗余,即两边各放一份,牺牲空间换效率;把不同的表放在不同的数据库上只适合于不太大的表;没看到太多的关于Facebook的介绍,(暂时也没有时间,先完成这个系列再说,坑里不再挖坑
 )不过Facebook的规模比Flickr要大得多,根据2008年的数据,Flickr的服务器数量大约是几百台,而Facebook是上万台,光Memcached服务器就有6,7百台,也可能是象你说的,不过应该更进一步,关于论坛的数据库在一个Shard集群(包括中央数据库和多个Shard)上,在线聊天的又在另一个上……
)不过Facebook的规模比Flickr要大得多,根据2008年的数据,Flickr的服务器数量大约是几百台,而Facebook是上万台,光Memcached服务器就有6,7百台,也可能是象你说的,不过应该更进一步,关于论坛的数据库在一个Shard集群(包括中央数据库和多个Shard)上,在线聊天的又在另一个上…… Shard+Memcached基本上是各大网站的事实标准了。
家园 送花得宝 恭喜:你意外获得【通宝】一枚鲜花已经成功送出。
此次送花为【有效送花赞扬,涨乐善、声望】
[返回] [关闭]
家园 Shard的写入似乎没有事务控制? 如果用户x在向shard A写数据的过程中,shard A崩溃了,那么会有以下后果:
* write through cache继续更新中央数据库
* 用户x刚刚写入shard A的数据全部丢失
这种情况flickr是怎么处理的?
家园 欢迎讨论 根据我的理解,例如用户注册应该是只更新中央数据库,而添加照片则是只写Shard,如果添加照片的过程中Shard挂了,则写入失败。
在Flickr的应用逻辑上不应该存在要同时写中央数据库和Shard情况存在,感觉这与Shard的设计初衷不符,否则要么就是我的理解有问题,要么就是Write through cache也负责更新shard?