- 近期网站停站换新具体说明
- 按以上说明时间,延期一周至网站时间26-27左右。具体实施前两天会在此提前通知具体实施时间
主题:【原创】解剖Twitter 【1】 -- 邓侃
家园 剖析的简单明了。好文 家园 谢谢:作者意外获得【西西河通宝】一枚推荐成功 对不起,好久不来这个版面了
家园 多谢版主举荐! 有空常回来看看。
家园 【原创】【4】抗洪需要隔离 【4】抗洪需要隔离
如果说如何巧用Cache是Twitter的一大看点,那么另一大看点是它的消息队列(Message Queue)。为什么要使用消息队列?[14]的解释是“隔离用户请求与相关操作,以便烫平流量高峰 (Move operations out of the synchronous request cycle, amortize load over time)”。
为了理解这段话的意思,不妨来看一个实例。2009年1月20日星期二,美国总统Barack Obama就职并发表演说。作为美国历史上第一位黑人总统,Obama的就职典礼引起强烈反响,导致Twitter流量猛增,如Figure 4 所示。
 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改Figure 4. Twitter burst during the inauguration of Barack Obama, 1/20/2009, Tuesday
Courtesy http://farm3.static.flickr.com/2615/4071879010_19fb519124_o.png
其中洪峰时刻,Twitter网站每秒钟收到350条新短信,这个流量洪峰维持了大约5分钟。根据统计,平均每个Twitter用户被120人“追”,这就是说,这350条短信,平均每条都要发送120次 [16]。这意味着,在这5分钟的洪峰时刻,Twitter网站每秒钟需要发送350 x 120 = 42,000条短信。
面对洪峰,如何才能保证网站不崩溃?办法是迅速接纳,但是推迟服务。打个比方,在晚餐高峰时段,餐馆常常客满。对于新来的顾客,餐馆服务员不是拒之门外,而是让这些顾客在休息厅等待。这就是[14] 所说的 “隔离用户请求与相关操作,以便烫平流量高峰”。
如何实施隔离呢?当一位用户访问Twitter网站时,接待他的是Apache Web Server。Apache做的事情非常简单,它把用户的请求解析以后,转发给Mongrel Rails Sever,由Mongrel负责实际的处理。而Apache腾出手来,迎接下一位用户。这样就避免了在洪峰期间,用户连接不上Twitter网站的尴尬局面。
虽然Apache的工作简单,但是并不意味着Apache可以接待无限多的用户。原因是Apache解析完用户请求,并且转发给 Mongrel Server以后,负责解析这个用户请求的进程(process),并没有立刻释放,而是进入空循环,等待Mongrel Server返回结果。这样,Apache能够同时接待的用户数量,或者更准确地说,Apache能够容纳的并发的连接数量(concurrent connections),实际上受制于Apache能够容纳的进程数量。Apache系统内部的进程机制参见Figure 5,其中每个Worker代表一个进程。
Apache能够容纳多少个并发连接呢?[22]的实验结果是4,000个,参见Figure 6。如何才能提高Apache的并发用户容量呢?一种思路是不让连接受制于进程。不妨把连接作为一个数据结构,存放到内存中去,释放进程,直到 Mongrel Server返回结果时,再把这个数据结构重新加载到进程上去。
事实上Yaws Web Server[24],就是这么做的[23]。所以,Yaws能够容纳80,000以上的并发连接,这并不奇怪。但是为什么Twitter用 Apache,而不用Yaws呢?或许是因为Yaws是用Erlang语言写的,而Twitter工程师对这门新语言不熟悉 (But you need in house Erlang experience [17])。
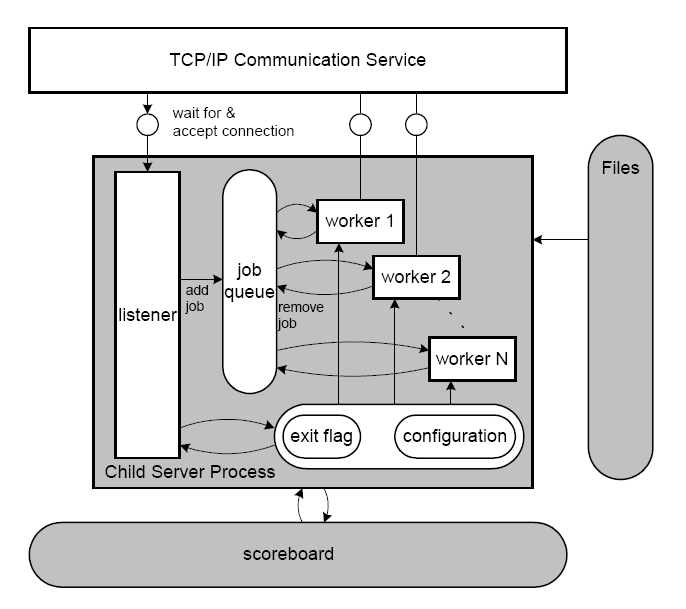 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改Figure 5. Apache web server system architecture [21]
Courtesy http://farm3.static.flickr.com/2699/4071355801_db6c8cd6c0_o.png
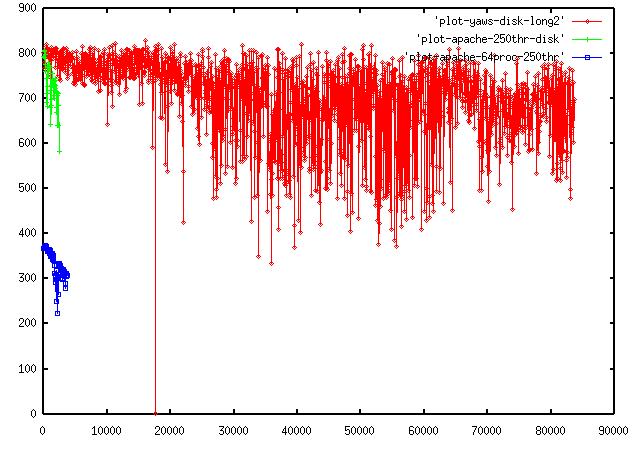 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改Figure 6. Apache vs. Yaws. The horizonal axis shows the parallel requests, the vertical one shows the throughput (KBytes/second). The red curve is Yaws, running on NFS. The blue one is Apache, running on NFS, while the green one is also Apache but on a local file system. Apache dies at about 4,000 parallel sessions, while Yaws is still functioning at over 80,000 parallel connections. [22]
Courtesy http://farm3.static.flickr.com/2709/4072077210_3c3a507a8a_o.jpg
Reference,
[14] Improving running component of Twitter. (http://qconlondon.com/london-2009/file?path=/qcon-london-2009/slides/EvanWeaver_ImprovingRunningComponentsAtTwitter.pdf)
[16] Updating Twitter without service disruptions. (http://gojko.net/2009/03/16/qcon-london-2009-upgrading-twitter-without-service-disruptions/)
[17] Fixing Twitter. (http://assets.en.oreilly.com/1/event/29/Fixing_Twitter_Improving_the_Performance_and_Scalability_of_the_World_s_Most_Popular_Micro-blogging_Site_Presentation%20Presentation.pdf)
[21] Apache system architecture. (http://www.fmc-modeling.org/download/publications/groene_et_al_2002-architecture_recovery_of_apache.pdf)
[22] Apache vs Yaws. (http://www.sics.se/~joe/apachevsyaws.html)
[23] 质疑Apache和Yaws的性能比较. (http://www.javaeye.com/topic/107476)
[24] Yaws Web Server. (http://yaws.hyber.org/)
[25] Erlang Programming Language. (http://www.erlang.org/)
通宝推:高子山,家园 【原创】【3】Cache == Cash 【3】Cache == Cash
Cache == Cash,缓存等于现金收入。虽然这话有点夸张,但是正确使用缓存,对于大型网站的建设,是至关重要的大事。网站在回应用户请求时的反应速度,是影响用户体验的一大因素。而影响速度的原因有很多,其中一个重要的原因在于硬盘的读写(Disk IO)。
Table 1 比较了内存(RAM),硬盘(Disk),以及新型的闪存(Flash)的各个性能。硬盘的读写,速度比内存的慢了百万倍。所以,要提高网站的速度,一个重要措施是尽可能把数据缓存在内存里。当然,在硬盘里也必须保留一个拷贝,以此防范万一由于断电,内存里的数据丢失的情况发生。
 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改Table 1. Storage media comparison of Disk, Flash and RAM [13]
Courtesy http://farm3.static.flickr.com/2736/4060534279_f575212c12_o.png
Twitter工程师认为,一个用户体验良好的网站,当一个用户请求到达以后,应该在平均500ms以内完成回应。而Twitter的理想,是达到200ms- 300ms的反应速度[17]。因此在网站架构上,Twitter大规模地,多层次多方式地使用缓存。Twitter在缓存使用方面的实践,以及从这些实践中总结出来的经验教训,是Twitter网站架构的一大看点。
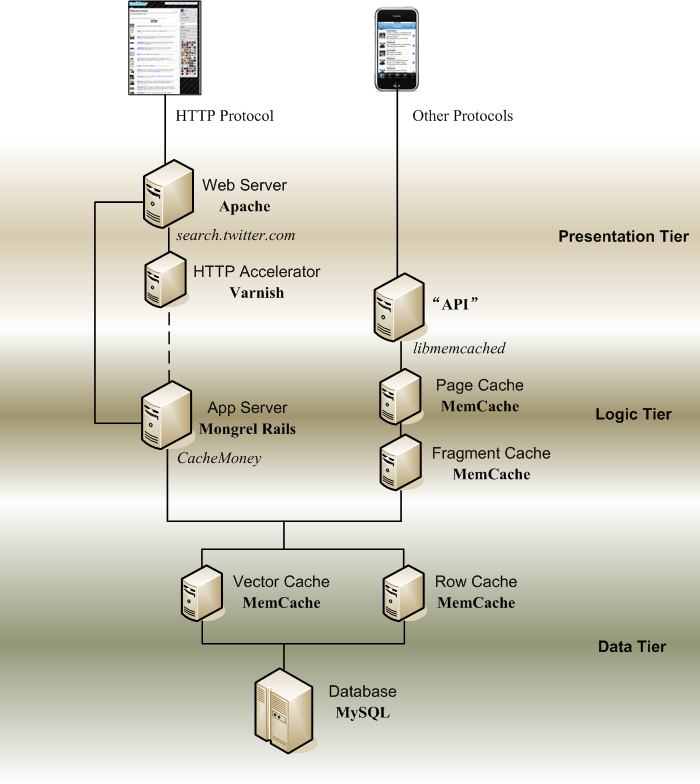 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改Figure 2. Twitter architecture with Cache
Courtesy http://farm3.static.flickr.com/2783/4065827637_bb2ccc8e3f_o.png
哪里需要缓存?越是Disk IO频繁的地方,越需要缓存。
前面说到,Twitter业务的核心有两个,用户和短信(Tweet)。围绕这两个核心,数据库中存放着若干表,其中最重要的有三个,如下所示。这三个表的设置,是旁观者的猜测,不一定与Twitter的设置完全一致。但是万变不离其宗,相信即便有所不同,也不会本质区别。
1. 用户表:用户ID,姓名,登录名和密码,状态(在线与否)。
2. 短信表:短信ID,作者ID,正文(定长,140字),时间戳。
3. 用户关系表,记录追与被追的关系:用户ID,他追的用户IDs (Following),追他的用户IDs (Be followed)。
有没有必要把这几个核心的数据库表统统存放到缓存中去?Twitter的做法是把这些表拆解,把其中读写最频繁的列放进缓存。
1. Vector Cache and Row Cache
具体来说,Twitter工程师认为最重要的列是IDs。即新发表的短信的IDs,以及被频繁阅读的热门短信的IDs,相关作者的IDs,以及订阅这些作者的读者的IDs。把这些IDs存放进缓存 (Stores arrays of tweet pkeys [14])。在Twitter文献中,把存放这些IDs的缓存空间,称为Vector Cache [14]。
Twitter工程师认为,读取最频繁的内容是这些IDs,而短信的正文在其次。所以他们决定,在优先保证Vector Cache所需资源的前提下,其次重要的工作才是设立Row Cache,用于存放短信正文。
命中率(Hit Rate or Hit Ratio)是测量缓存效果的最重要指标。如果一个或者多个用户读取100条内容,其中99条内容存放在缓存中,那么缓存的命中率就是99%。命中率越高,说明缓存的贡献越大。
设立Vector Cache和Row Cache后,观测实际运行的结果,发现Vector Cache的命中率是99%,而Row Cache的命中率是95%,证实了Twitter工程师早先押注的,先IDs后正文的判断。
Vector Cache和Row Cache,使用的工具都是开源的MemCached [15]。
2. Fragment Cache and Page Cache
前文说到,访问Twitter网站的,不仅仅是浏览器,而且还有手机,还有像QQ那样的电脑桌面工具,另外还有各式各样的网站插件,以便把其它网站联系到 Twitter.com上来[12]。接待这两类用户的,是以Apache Web Server为门户的Web通道,以及被称为“API”的通道。其中API通道受理的流量占总流量的80%-90% [16]。
所以,继Vector Cache和Row Cache以后,Twitter工程师们把进一步建筑缓存的工作,重点放在如何提高API通道的反应速度上。
读者页面的主体,显示的是一条又一条短信。不妨把整个页面分割成若干局部,每个局部对应一条短信。所谓Fragment,就是指页面的局部。除短信外,其它内容例如Twitter logo等等,也是Fragment。如果一个作者拥有众多读者,那么缓存这个作者写的短信的布局页面(Fragment),就可以提高网站整体的读取效率。这就是Fragment Cache的使命。
对于一些人气很旺的作者,读者们不仅会读他写的短信,而且会访问他的主页,所以,也有必要缓存这些人气作者的个人主页。这就是Page Cache的使命。
Fragment Cache和Page Cache,使用的工具也是MemCached。
观测实际运行的结果,Fragment Cache的命中率高达95%,而Page Cache的命中率只有40%。虽然Page Cache的命中率低,但是它的内容是整个个人主页,所以占用的空间却不小。为了防止Page Cache争夺Fragment Cache的空间,在物理部署时,Twitter工程师们把Page Cache分离到不同的机器上去。
3. HTTP Accelerator
解决了API通道的缓存问题,接下去Twitter工程师们着手处理Web通道的缓存问题。经过分析,他们认为Web通道的压力,主要来自于搜索。尤其是面临突发事件时,读者们会搜索相关短信,而不理会这些短信的作者,是不是自己“追”的那些作者。
要降低搜索的压力,不妨把搜索关键词,及其对应的搜索结果,缓存起来。Twitter工程师们使用的缓存工具,是开源项目Varnish [18]。
比较有趣的事情是,通常把Varnish部署在Web Server之外,面向Internet的位置。这样,当用户访问网站时,实际上先访问Varnish,读取所需内容。只有在Varnish没有缓存相应内容时,用户请求才被转发到Web Server上去。而Twitter的部署,却是把Varnish放在Apache Web Server内侧 [19]。原因是Twitter的工程师们觉得Varnish的操作比较复杂,为了降低Varnish崩溃造成整个网站瘫痪的可能性,他们便采取了这种古怪而且保守的部署方式。
Apache Web Server的主要任务,是解析HTTP,以及分发任务。不同的Mongrel Rails Server负责不同的任务,但是绝大多数Mongrel Rails Server,都要与Vector Cache和Row Cache联系,读取数据。Rails Server如何与MemCached联系呢?Twitter工程师们自行开发了一个Rails插件(Gem),称为CacheMoney。
虽然Twitter没有公开Varnish的命中率是多少,但是[17]声称,使用了Varnish以后,导致整个Twitter.com网站的负载下降了50%,参见Figure 3.
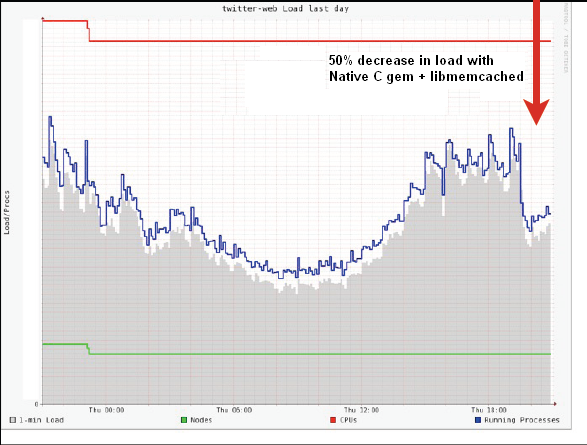 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改Figure 3. Cache decreases Twitter.com load by 50% [17]
Courtesy http://farm3.static.flickr.com/2537/4061273900_2d91c94374_o.png
Reference,
[12] Alphabetical List of Twitter Services and Applications. (http://en.wikipedia.org/wiki/List_of_Twitter_services_and_applications)
[13] How flash changes the DBMS world. (http://hansolav.net/blog/content/binary/HowFlashMemory.pdf)
[14] Improving running component of Twitter. (http://qconlondon.com/london-2009/file?path=/qcon-london-2009/slides/EvanWeaver_ImprovingRunningComponentsAtTwitter.pdf)
[15] A high-performance, general-purposed, distributed memory object caching system. (http://www.danga.com/memcached/)
[16] Updating Twitter without service disruptions. (http://gojko.net/2009/03/16/qcon-london-2009-upgrading-twitter-without-service-disruptions/)
[17] Fixing Twitter. (http://assets.en.oreilly.com/1/event/29/Fixing_Twitter_Improving_the_Performance_and_Scalability_of_the_World_s_Most_Popular_Micro-blogging_Site_Presentation%20Presentation.pdf)
[18] Varnish, a high-performance HTTP accelerator. (http://varnish.projects.linpro.no/)
[19] How to use Varnish in Twitter.com? (http://projects.linpro.no/pipermail/varnish-dev/2009-February/000968.html)
[20] CacheMoney Gem, an open-source write-through caching library. (http://github.com/nkallen/cache-money)
通宝推:高子山,家园 【原创】解剖Twitter 【2】三段论 【2】三段论
网站的架构设计,传统的做法是三段论。所谓“传统的”,并不等同于“过时的”。大型网站的架构设计,强调的是实用。新潮的设计,固然吸引人,但是技术可能不成熟,风险高。所以,很多大型网站,走的是稳妥的传统的路子。
2006年5月Twitter刚上线的时候,为了简化网站的开发,他们使用了Ruby-On-Rails工具,而Ruby-On-Rails的设计思想,就是三段论。
1. 前段,即表述层(Presentation Tier) 用的工具是Apache Web Server,主要任务是解析HTTP协议,把来自不同用户的,不同类型的请求,分发给逻辑层。
2. 中段,即逻辑层 (Logic Tier)用的工具是Mongrel Rails Server,利用Rails现成的模块,降低开发的工作量。
3. 后段,即数据层 (Data Tier) 用的工具是MySQL 数据库。
先说后段,数据层。
Twitter 的服务,可以概括为两个核心,1. 用户,2. 短信。用户与用户之间的关系,是追与被追的关系,也就是Following和Be followed。对于一个用户来说,他只读自己“追”的那些人写的短信。而他自己写的短信,只有那些“追”自己的人才会读。抓住这两个核心,就不难理解 Twitter的其它功能是如何实现的[7]。
围绕这两个核心,就可以着手设计Data Schema,也就是存放在数据层(Data Tier)中的数据的组织方式。不妨设置三个表[8],
1. 用户表:用户ID,姓名,登录名和密码,状态(在线与否)。
2. 短信表:短信ID,作者ID,正文(定长,140字),时间戳。
3. 用户关系表,记录追与被追的关系:用户ID,他追的用户IDs (Following),追他的用户IDs (Be followed)。
再说中段,逻辑层。
当用户发表一条短信的时候,执行以下五个步骤,
1. 把该短信记录到“短信表” 中去。
2. 从“用户关系表”中取出追他的用户的IDs。
3. 有些追他的用户目前在线,另一些可能离线。在线与否的状态,可以在“用户表”中查到。过滤掉那些离线的用户的IDs。
4. 把那些追他的并且目前在线的用户的IDs,逐个推进一个队列(Queue)中去。
5. 从这个队列中,逐个取出那些追他的并且目前在线的用户的IDs,并且更新这些人的主页,也就是添加最新发表的这条短信。
以上这五个步骤,都由逻辑层(Logic Tier)负责。前三步容易解决,都是简单的数据库操作。最后两步,需要用到一个辅助工具,队列。队列的意义在于,分离了任务的产生与任务的执行。
队列的实现方式有多种,例如Apache Mina[9]就可以用来做队列。但是Twitter团队自己动手实现了一个队列,Kestrel [10,11]。Mina与Kestrel,各自有什么优缺点,似乎还没人做过详细比较。
不管是Kestrel还是Mina,看起来都很复杂。或许有人问,为什么不用简单的数据结构来实现队列,例如动态链表,甚至静态数组?如果逻辑层只在一台服务器上运行,那么对动态链表和静态数组这样的简单的数据结构,稍加改造,的确可以当作队列使用。Kestrel和Mina这些“重量级”的队列,意义在于支持联络多台机器的,分布式的队列。在本系列以后的篇幅中,将会重点介绍。
最后说说前段,表述层。
表述层的主要职能有两个,1. HTTP协议处理器(HTTP Processor),包括拆解接收到的用户请求,以及封装需要发出的结果。2. 分发器(Dispatcher),把接收到的用户请求,分发给逻辑层的机器处理。如果逻辑层只有一台机器,那么分发器无意义。但是如果逻辑层由多台机器组成,什么样的请求,发给逻辑层里面哪一台机器,就大有讲究了。逻辑层里众多机器,可能各自专门负责特定的功能,而在同功能的机器之间,要分摊工作,使负载均衡。
访问Twitter网站的,不仅仅是浏览器,而且还有手机,还有像QQ那样的电脑桌面工具,另外还有各式各样的网站插件,以便把其它网站联系到Twitter.com上来[12]。因此,Twitter的访问者与Twitter网站之间的通讯协议,不一定是HTTP,也存在其它协议。
三段论的Twitter架构,主要是针对HTTP协议的终端。但是对于其它协议的终端,Twitter的架构没有明显地划分成三段,而是把表述层和逻辑层合二为一,在Twitter的文献中,这二合一经常被称为“API”。
综上所述,一个能够完成Twitter基本功能的,简单的架构如Figure 1 所示。或许大家会觉得疑惑,这么出名的网站,架构就这么简单?Yes and No,2006年5月Twitter刚上线的时候,Twitter架构与Figure 1差距不大,不一样的地方在于加了一些简单的缓存(Cache)。即便到了现在,Twitter的架构依然可以清晰地看到Figure 1 的轮廓。
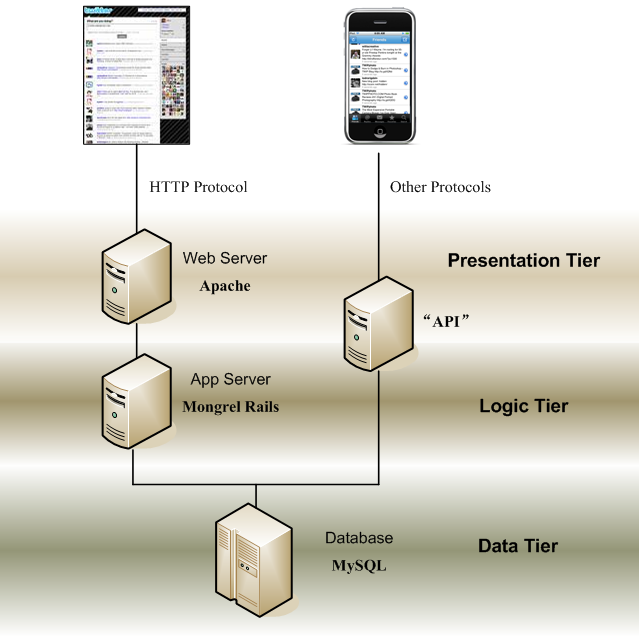 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改Figure 1. The essential 3-tier of Twitter architecture
Courtesy http://farm3.static.flickr.com/2683/4051785892_e677ae9d33_o.png
Reference,
[7] Tweets中常用的工具 (http://www.ccthere.com/article/2383833)
[8] 构建基于PHP的微博客服务 (http://webservices.ctocio.com.cn/188/9092188.shtml)
[9] Apache Mina Homepage (http://mina.apache.org/)
[10] Kestrel Readme (http://github.com/robey/kestrel)
[11] A Working Guide to Kestrel. (http://github.com/robey/kestrel/blob/master/docs/guide.md)
[12] Alphabetical List of Twitter Services and Applications (http://en.wikipedia.org/wiki/List_of_Twitter_services_and_applications)
通宝推:高子山,家园 先送花,再来挑个刺。呵呵 队列的实现方式有多种,例如Apache Mina[9]就可以用来做队列。但是Twitter团队自己动手实现了一个队列,Kestrel [10,11]。Mina与Kestrel,各自有什么优缺点,似乎还没人做过详细比较。mina是个java 的socket开发框架,我们可以用mina来开发http server/ftp server/消息队列等各种socket server,属于底层框架;而Kestrel应该就是个消息队列,应该是上层应用。放在一起似乎不太合适阿,呵呵。
Apache MINA is a network application framework which helps users develop high performance and high scalability network applications easily. It provides an abstract · event-driven · asynchronous API over various transports such as TCP/IP and UDP/IP via Java NIO.mina我用的比较多,Kestrel不了解,说得不一定对,呵呵,


