主题:【讨论】deepseek目前的相对位置 -- 陈王奋起
- 共: 💬 6 🌺 61
- 新: 💬 1
家园 【讨论】deepseek目前的相对位置 自从deepseek发布以来,它的水平如何,各方出于各自的目的,发表了许多观点和看法,这些主观的东西很难作为讨论的基础。
UC Berkeley的一些学生发起了一个双盲匿名投票的大模型竞技平台Chatbot arena(此处应该@懒厨 兄),让数以百万计的使用者人肉投票。
下图是截至到2025年2月15日的排行榜:
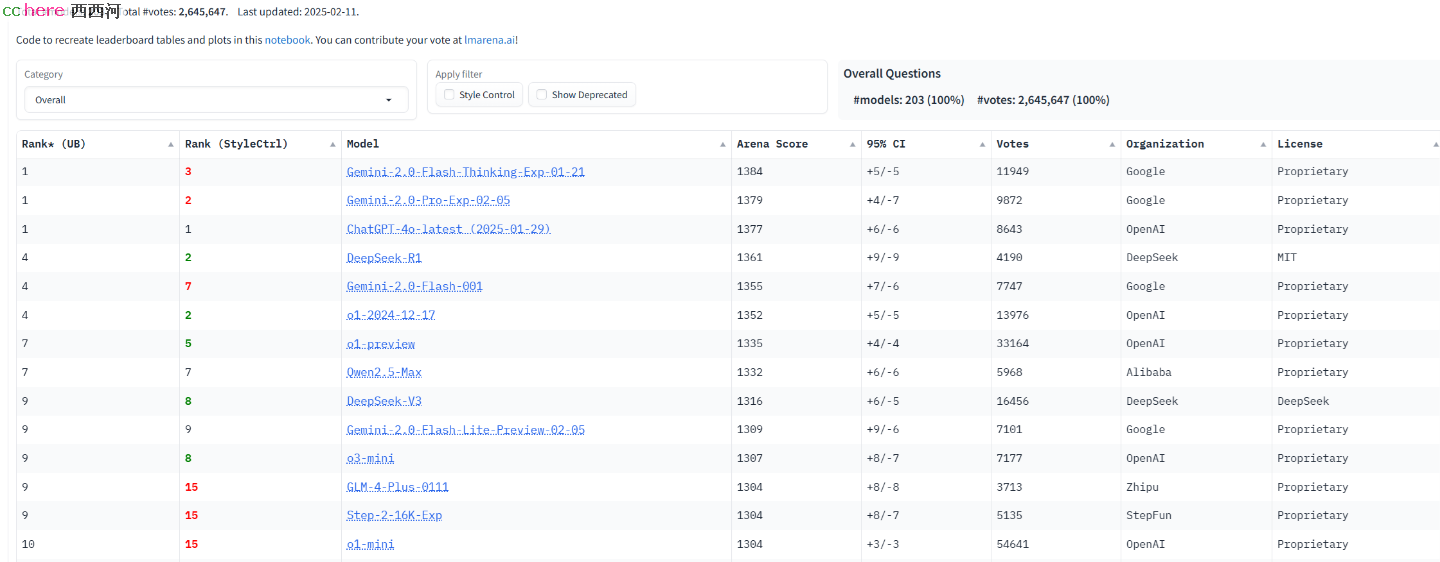
Deepseek R1目前排名第4,前面3位都是刚刚发布3周以内的闭源平台,得分差别大约1%。相当于你富家子砸钱请名师,考了99分,我穷小子裸奔考了98分,然后我把我的学习笔记和心得免费传授。
网址:https://lmarena.ai/?leaderboard
通宝推:红十月,家园 直观体现能力指标的办法之一 OAI秘密赞助EpochAi,FrontierMath刷榜嫌疑曝光后,不同的大模型竞技场结果值得再考量🧐
一些其它因素随便谈谈
close ai用api都存在严重降智现象,长期使用的用户体会明显。按奥特曼近期暗示,“o3不独立发布;GPT5起,o和GPT系列集成;以后根据prompt自动选择调用哪个模型”。如果前台打包成一个,用户无法选择模型,更理直气壮后台降智了。
o3mini提供的也不是原始cot,X讨论很多不赘述了,“the new CoT is a new CoT summarizer”。不过dsR1面世前,o1用户追问cot甚至会导致封号。这次ds无推广破圈,用户能毫无保留阅读ai思考过程是重要因素
【当我问Deepseek要核弹发射密码,结果...-哔哩哔哩】 假设该视频只能看到答案,效果-90%
qwen时至今日普通人缺乏快捷方便的体验渠道,分不清哪个模型是能力最强的新版。注重用户拉新、体验的豆包是该坐标系另一端(模型能力另说)
家园 大模型没有品牌粘性,类似跟电力一样,谁好谁便宜就用谁 这个生意模型太残酷了,deepseek本质上重构了AI基础设施的商业模式。
家园 我用的还挺爽 服务器繁忙半夜用就行了,只是网页版本的模型有字数限制和法律敏感词限制,提问的时候精确问就行了,这狗头军师太靠谱了。