- 近期网站停站换新具体说明
- 按以上说明时间,延期一周至网站时间26-27左右。具体实施前两天会在此提前通知具体实施时间
主题:【半原创】Flickr 网站架构研究(1) -- 西电鲁丁
memcache看了一下简介
Memcached is an in-memory key-value store for small chunks of arbitrary data (strings, objects) from results of database calls, API calls, or page rendering.
那么就是说memcache全部是in-memory 操作,那么hash的开销是C,全部都是mem的话,对小数据量来说,这个速度就超快了。但因为全部都是memory,所以必须要多台机器来cache。这个如何管理distributed cache是个很大的课题,没有考察过,不好说了。
Flickr系列已经接近尾声,这一段时间一直在考虑下一个研究的目标,目前有三个候选,facebook,amazon,google. Facebook的挑战是它的复杂程度,而对amazon和google的兴趣则在于两者作为典型的infrastrature cloud和application cloud所搭建云计算的基础架构。无论那一个,所需要收集的资料,花费的时间,和研究的难度都会要大得多,尽力而为吧。
坑底静候。。。
眼看要放假出游了,最好搞个PDF合集,方便随身携带,有空就拿出来翻翻。
花等好文。
春节几日,应酬频繁,心绪烦乱。这时候,手头如果有篇好文,有助于让浮躁的心,平静下来。
盼望看到西电兄对Amazon的研究。
最后来说一说"Stoage Manager"。最早的Flickr系统是没有这一层的,Web/PHP Server在收到用户上载的照片后直接通过NFS协议将照片文件写入后台的NetApp存储。这样带来的问题是:
1。NFS协议的“文件传输”效率成为瓶颈。高效网络文件传输的要点在于使用尽可能大的数据报文和尽量减少传输控制报文的开销,不幸的是,NFS在这两点上都差强人意。
早期的NFS version 2.0使用UDP作为传输协议,但一次最大只能传输8KB.NFS version 3.0消除了这个8KB的限制,并引入了“异步写”的概念,理论上可以将多个小的“写”缓存在“cache”中再合并成一个大的写操作而提高效率,但在实际中往往要看协议的实现情况和操作系统内核的支持,比如至少在早期的LINUX实现中并不理想。
2004年初,University of Massachusetts & IBM Almaden Research Center & University of California联合做了一项关于比较NFS和iSCSI应用于IP存储性能的研究,“A Performance Comparison of NFS and iSCSI for IP-Networked Storage”。在这份研究中,其中一项是在网络协议层比较两者“顺序和随机读写“的效率,结果见下图
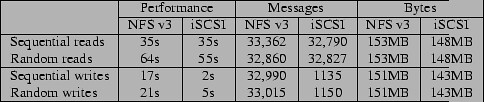
我们看到NFSv3的“读”效率和iSCSI基本相当,但在写效率上则有数量级上的差距。从网络协议报文的数量上看,iSCSI远远小于NFSv3,这是因为iSCSI能够以较大的数据包(大约128KB)执行异步写操作,而NFSv3的平均数据包只有4.7KB,其原因是NFSv3在Linux上的实现受到了Linux 内核2.4 cache最大“pending write"数量的限制因而不能充分利用异步写所带来的好处。
在另一项应用层的测试中,研究人员使用PostMark测试了两者在创建,删除,读和附加(append)文件的效率,结果如下:
Completion time (s) Messages
Files NFSv3 iSCSI NFS v3 iSCSI
1,000 146 12 371,963 101
5,000 201 35 451,415 276
25,000 516 208 639,128 66,965
这项测试表明NFSv3协议在文件相关操作中有非常高的"meta-data related overhead",研究人员在分析上面的测试结果发现这一类message占全部message数量的65%。
同样是在2004年,一些操作系统包括Linux等开始部分支持NFSv4。NFSv4除了采用了TCP之外,引入了一些新的特性,其中之一是“Compound RPCs",即可以一次发送多个RFC请求并取得结果,这样无疑可以大大减少"meta-data"相关的开销,显著的提高协议的总体效率。另一方面,随着Linux内核2.6的成熟并得到逐步采用,Linux在NFS的实现上也有了很大的提高,例如消除了"pending write" 数量的限制等。
然而不幸的是,这些提高对于Flickr所需的“大文件传输”并没有帮助。根据“NFSv4 Test Project”的测试结果
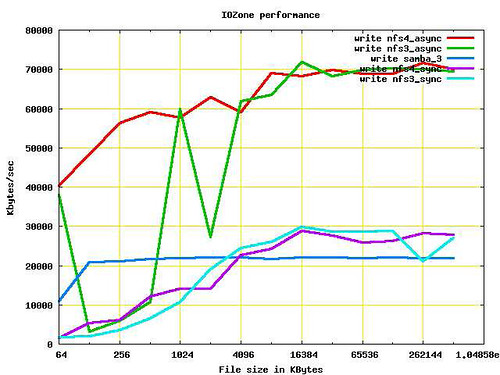
在异步模式下,对于小于512KB的文件,NFSv4(红线)大约是NFSv3 (绿线)效率的3倍,但对于大文件和同步模式,则几乎相当或略有提高。
另一项2008年的测试表明,在File Creation操作上,NFSv4甚至要慢于NFSv3.
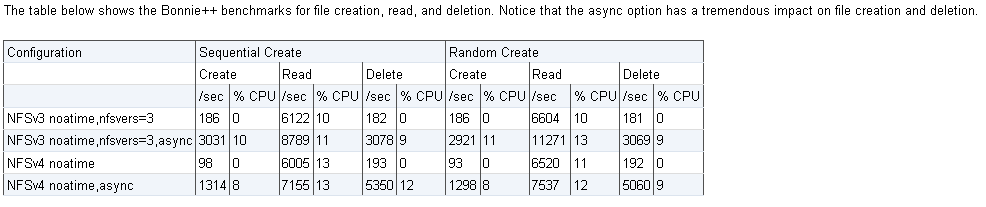
究其原因,NFS是以支持"文件共享"为主要目的,侧重于多路并发访问条件下文件内的修改和同步控制。但是对于"文件传输"为主要目的的应用来说,这些额外的同步和锁机制就成为多余和不必要的开销。
那么Flickr为什么不用FTP呢?FTP的主要问题是FTP需要两个端口,一个用于传输实际的文件,另一个用于传输控制命令。我们知道一台机器的端口(0-65535)是有限的,除去保留的系统端口外,真正能用的不过6万3千多个,而在一个高负载的,每秒成千上万访问的环境中,操作系统很容易出现“端口耗尽“的情况而拒绝新的连接。笔者曾经作过一个测试,在200个线程并发访问,每个线程平均5-10秒一笔交易下,30分钟左右,一台缺省配置的Windows 2003 Server就提示端口用尽。虽然可以通过调整Windows注册表或UNIX内核参数即减少tcp wait time的值来加快tcp端口的释放,但毕竟不如只用一个端口。
2。Web/PHP Server直连NetApp的另一个坏处我想大家都应该想到了,那就是应用层和存储管理层绑定的太紧。在直连的情况下,每一台Server都要Mount全部的NFS卷,而任一个NFS卷的故障都可能会影响到所有的Web服务器,或者至少每一个服务器在写操作之前,都要检查目标卷是否可用,如果标记为故障的话要选择并写到另一个卷;而且还要监控所有卷的使用情况,在卷剩余空间小于阀值或者文件数多于阀值时报警并将此卷置为”只读“等。
这些最终导致了专门负责存储管理和写操作的Storage Manager层的出现。Flickr为Web/PHP Server和Storage Manager之间专门设计了”轻量文件传输协议“。协议的主要编码规则如下:
请求:
|STORE|number files|{file1}|{file2}|{file3}|...
每一个{file}块的格式:
|filename|leading byte|file content byte length|file content|
leading byte的值是”file content byte length"字符串的长度。例如1MB的文件,file content byte length 是1048576,则leading byte的值是"1048576"的长度7.
响应:
|OK|volume number of where the file store| or
|Failed|the reason of failed|
协议本身是非常简单的,而且可以在一个报文里传输多个文件。而接受程序则根据文件长度直接截取文件内容,省去了诸如base64等编解码的开销。整个协议代码约600行PHP,包括opening,closing sockets, hot failover to redundant servers, and safe read and writes等.
Web/PHP端的调用示例如下:
function store_file($storage_hosts, $filename){
shuffle($storage_hosts);
foreach($storage_hosts as $host){
$result = store_file_2($host, $filename);
if ($result){ return $result; }
}
return 0;
}
function store_file_2($host, $filename){
...
if ($connection_failed){
return 0;
}
...
if ($operation_failed){
return 0;
}
return $result;
}
代码中的storage_hosts既是Farm中的几台Storage Manager,和前面介绍过的db_query一样,上述代码也实现了简单而有效的load balance.
Storage Manager接受到文件后,将文件放入Offline Queue队列,再由专门的图像处理服务器进行整理,压缩和格式转化(如果需要的话),生成不同尺寸大小的文件,并通过NFS写入NetApp存储。虽然这一步仍然要通过NFS,但此时的操作已是非实时,效率的影响已经不大了。
应当指出,除非不得已,在绝大多数情况下,放弃成熟的公共协议而构建自己的私有协议并非上策。而笔者在文中列出的NFS和FTP的不足,也只是说明当前版本的NFS和FTP不适合于Flickr的特殊应用要求而已。 (NFS的优化不在本文讨论范围内,有兴趣的读者可以参考以下连接:[URL=http://media.netapp.com/documents/tr-3183.pdf
]NetApp的关于NFS Linux白皮书[/URL]和NFS-HOWTO)
那么有没有协议可以满足此类要求呢?个人认为值得关注的有:一。NFS4.1:NFS4.1版本将支持pNFS,即并行NFS,pNFS是近20年来NFS首次在性能上的重大升级,将可能成为高性能、共享文件存储的未来;另一个是SAN+Cluster FileSystem(如RedHat的Global File System和IBM的General Parallel File System)。传统上的SAN协议不直接支持多路并发写,而Cluster FS则弥补了这一缺陷为底层的共享块设备在文件系统级别提供并发的读写功能,因此更能发挥SAN存储架构的协议性能优势。有兴趣的话,大家可以看看这篇文章Red Hat GFS vs. NFS: Improving performance and scalability
象facebook什么的,都有api,如果能大致介绍一下实现的框架也很好。很想多了解一些这方面的内容。眼下还不知道从何下手。
本来计划中Flickr还有最后一篇关于系统监控和容量规划的,答应了邓侃兄春节前写完的。
不过既然铁手大人发话了,那就春节后写一篇“续”或者“补”吧。
之前找到一个基于django的sns框架pinax,在看Flickr架构分析时不自觉地将Flickr和django/pinax作对比,有很多不同之处。希望能听听楼主对sns类架构的分析。