- 近期网站停站换新具体说明
- 按以上说明时间,延期一周至网站时间26-27左右。具体实施前两天会在此提前通知具体实施时间
主题:【原创】官话诗词 -- jent
一个中等规模的统计,关于同音字
2021-04-05
对于我们的汉语,大家都知道,字,比音多。就是说,有很多的同音字。
那么,究竟有多少呢,这些同音字又从何而来?有人说,这有何难,翻一番新华字典不就知道了么?是的,有些东西,光翻新华字典,是不能知道的,比如,下面我要说的。
在跟着女儿学习了71首古诗词,一千多个汉字之后,算是有了一个中等规模的结论。之所以说是中等规模,是因为常用汉字约2500左右。一千余汉字,分布在从先秦到共和国时代的历朝历代古诗词中,而且几乎有一半是在现今中国大陆的小学课本里的必学必背古诗词,剩下一半也都是大家耳熟能祥的,比如“明月几时有,把酒问青天”,或者“所谓伊人,在水一方”之类的名篇,这样的一千余汉字,应该算得上有一定的代表性,算得上中等规模的数据,在其上所得出的结论,应该可以算得上中等规模的结论了。
当然,不排除未来更多的汉字学习加入到这个统计,并导致一些结论的改变,但是我相信,大致的结论是不会有什么误差的。
OK,言归正传。
目前已经收录在女儿的汉语学习资料库里的1096个汉字,在国语/普通话拼音读音体系下,同音字最多的一个音(不管其声调),是“yi”这个音,目前总共有24个字:
“已右以异夷衣依意伊倚羿遗疑忆憶亿億亦易一乙佚溢浥”
。而第二多的,是“qi”这个音,目前总共有20个字:
“弃绮骑企气岂起其棋期旗岐歧祇齐妻萋凄泣七”
。第三多的,是“shi”这个音,目前有19个字:
“氏世时市师使始诗事是势石识轼饰蚀失十湿”
。。。接下来,是“ji”这个音,17个字,“yu”这个音,17个字,“zhi”这个音,15字,“wei”这个音,14字,“jie”这个音,14字,“wu”这个音,13字,“jian”这个音,12字,“jing”这个音,12字,“fu”这个音,11字,“xi”这个音,11字。。。
这么粗略一看,至少有13个读音,是各自超过了10个字的,这还不是完全统计(1000余常用汉字)。
有人问,超过就超过呗,有什么了不起的?
不,说一个大家都知道的事情:汉语拼音输入法,超过10个字的音,是否总是需要翻页翻来覆去查找所需要的字?如果要加上汉字智能排序,是否翻来覆去查找一个汉字更为不方便?
嗯,同样的这一批汉字,在官话语音体系中,分布是这样的:
同音字最多的音,是“yu”这个音15个字,接下来,是与“弃”同音的,有14个字,与“为”同音的,14字,与“以”同音的,13个字,接下来就是“zhi”12字,“wu”12字,“shi”11字,嗯,目前看就这7个音各自超过了10个字。
至于为什么,那就是很多人都知道的两个原因:1,尖团合流,比如在普通话里读“qi”这个音的20个字,里边就包含了官话里与“弃”同音的14个字,与“齐”同音的4个字,这18个普通话同音的汉字,分尖团的话,就分别为两组不同音的字了。2,入声排入:普通话/国语语音体系里边是没有入声的。而目前女儿所学到的20个读作“qi”的汉字里,有两个官话发音体系里的入声音:“泣”,“七“。同样的例子在普通话“yi”这个音里边的24个汉字里,只有13个在官话体系里边读作“yi”,剩下的,全部11个都是入声音,ktp结尾的分别是6个,4个,和1个。
另外两个不那么为人所知的原因,一个是官话体系里边的闭口韵归入到普通话体系里的前鼻韵,比如“剑”这个字,在官话体系里边既是舌后团音,又是闭口韵,用拉丁字母表示应该读作“giiam”这个音,但在尖团合流,以及闭口韵归前鼻韵的普通话/国语体系里,就读做“jian”这个音,和“箭”(官话里读作“ziian”)这个字同音同调了。另外一个小原因则更不大为人所注意,那就是在普通话/国语体系里,元音颚化之后所造成的,这里不再多说。
嗯,民间科学爱好者的小研究。喜欢的话点个赞吧。
现在拼音输入有时候有几个音会翻好多篇,是大麻烦,尤其是非常用字。
虽然还有其它的输入法,基于汉语拼音的输入依然是最大众的
等这两天自己的工作忙完了,我把老国语的发音加进去试试。
老国语跟新国语还是有很大的不同的。最主要的就是从韵书(老国语),还是从北京口语音(新国语/普通话)。前者分尖团,有入声。后者不分,无。
我的普通话本身就不好 ^_^
参见网页:
https://www.fm-wuyi.com/yiem/gh_index.html
里边添加了自动的官话读音标注,只标注了与普通话不一致的单字。当然,也可以直接通过单字读音查询,查询出两种不同语音体系下的各自读音来。
当然,也在逐步添加各古诗词的语音文件。暂时都是本人读的。读得不好,大家多担待。喜欢的话,给俺点个赞吧。
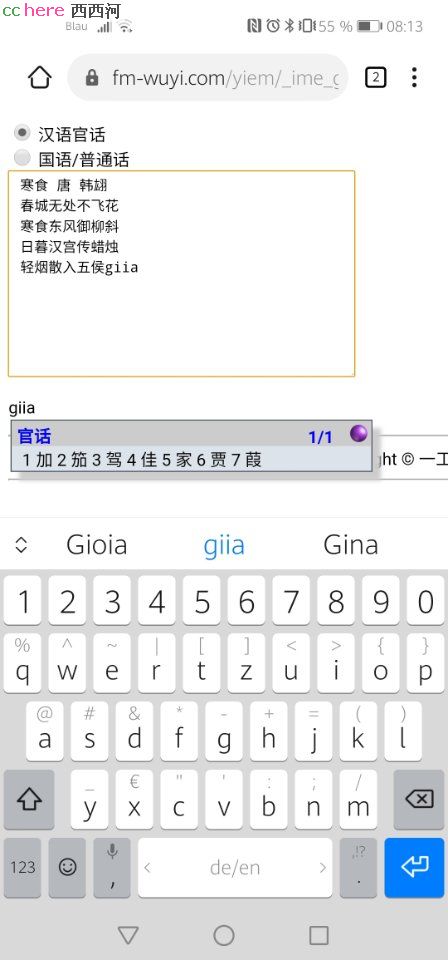
另外还有一个根据读音进行输入的输入法,也准备好了。等合适的时间再广而告之大家吧。
送元二使安西
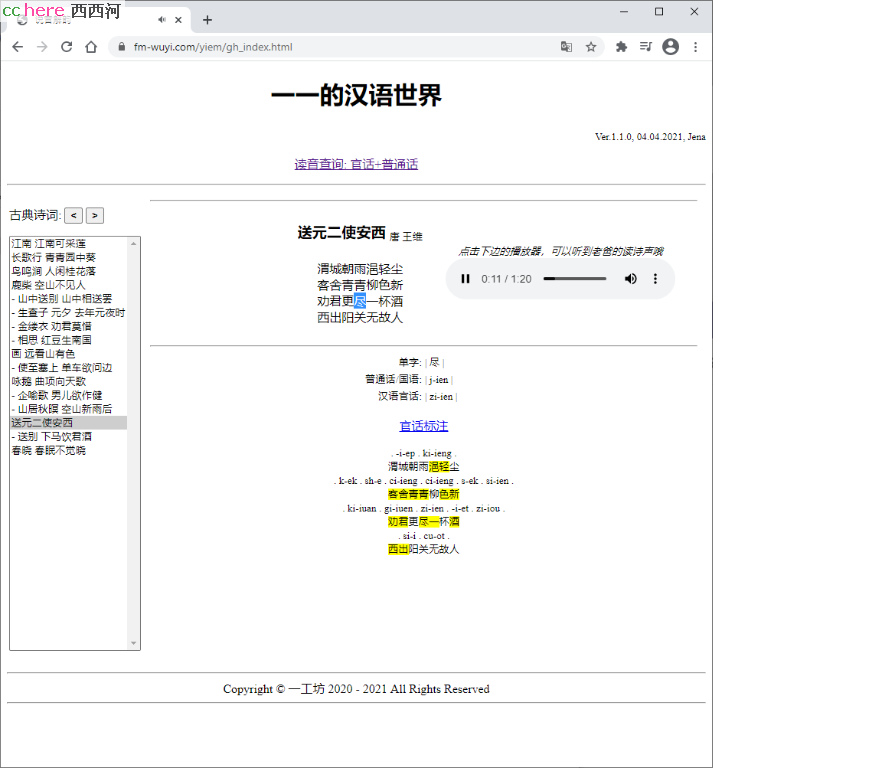
每天督促女儿写字读诗。从去年的圣诞假期到今天,一晃,快五个月了。
识字量已经到达1500门槛,包含了国内小学课本的古典诗词,和一些小学课本以外的。
这里边,所有的字按照读音分类,在普通话/国语发音体系下,分别如下:
齐齿韵,336字,包含所有 i (衣),ai (爱),ei (诶),uai (外),uei (喂) 等等韵母结尾的字。
合口韵,338字,包含所有 u (唔),iu (鱼),au (嗷),ou (鸥),iau (幺),iou (呦)等等韵母结尾的字。
元声韵,163字,包含所有 a (啊),o (哦),ia (呀),ye (也),ua (哇),uo (喔),iue (月)等等韵母结尾的字。
前鼻韵 ,343字,包含所有 an (安),en (嗯),ian (言),ien (因),uan (弯),uen (文),iuan (元),iuen (云)等等韵母结尾的字。
后鼻韵,278字,包含所有 ang (昂),eng (生),ong (东),iang (央),ieng (英),iong (永),uang (汪),ueng (翁)。
以及两个特殊的韵母:
普通话/国语体系下的 e 韵母:如 “ 娥得乐个可和这车社 。。。” 等等字,共有47个。
以及普通话/过于体系下的 er 韵母,“二儿而” 三个字。
当然,这只是目前所学到的约 100 余首古诗词里的汉字分布,如下:
齐齿韵:336
合口韵:338
元音韵:163
前鼻韵:343
后鼻韵:278
娥/儿 音:50
合计1508个字/音。
同样这 1500多个字,放到平水韵官话语音体系下,同样的原则,分布如下
齐齿韵:276
合口韵:295
元音韵:89
前鼻韵:266
后鼻韵:278
闭口韵 (am,em 结尾):77
ktp入声韵:231
娥/儿 音:无。
其中,官话里的闭口韵在普通话/国语体系里全部归为前鼻韵。
普通话/国语里的儿音全部归为官话里的齐齿韵(类似于 “尼” 的发音 )。
普通话/国语里的娥/音部分归为官话里的元音韵,部分归为官话里的入声韵。
其余普通话/国语和官话里齐齿/合口/元音韵的不同,几乎全部是因为入声韵在普通话/国语里没有位置导致。
嗯,算是一个阶段性(古典诗词1500余字的规模)的总结吧:
所谓入派三声(平上去),不如理解为入(韵)派三韵(齐齿,合口,元音)。
嗯,从圣诞节假期开始,到今天勘勘6个月了。跟着女儿(一一)重新学了一遍小学的古诗词,六个月下来林林总总170首,收编汉字1820多个。每个字的普通话/和官话的读音整理,一个比较完整的标注,输入,查询以及语音听取的系统基本成型。
达到并超过了一开始的目标。一个月节点,三个月节点,六个月节点,均顺利达成。是时候进行下一步的工作了:继续,以期到一年节点的时候,1,完成3500个常用及次常用汉字的读音整理。2,初步形成规律性的普通话<-->官话的双向转化功能,包含入声音,尖团音,闭口音,以及颚化音的各自字典化。
待一年期满,上述工作完成,则开始进入自动化拟音阶段。嗯,一步一个脚印,目前(六月节点)看,还是比较扎实,靠谱的。[调皮][呲牙][偷笑]

努力加油ing
嗯,第一阶段工作,完成了。
对常用汉字(一二级3500字基准)以及在小学课本的古诗词里出现的全部汉字,加起来约4600多个字/音,进行读音标注工作。
以现代汉语普通话/国语为基础,发音依照 a啊 o哦 e呃结尾 为元音韵,以 i 结尾,含 i咦,ai哎,ei诶,uai歪,uei喂等,为齐齿韵,以u结尾,含u呜,iu吁,au嗷,ou呕,iau吆,iou呦等等,为合口韵,以n结尾,含an安,en嗯,ian烟,ien因,uan弯,uen文,iuan元,iuen云等等,为前鼻韵,以ng结尾,含ang,eng,ong,iang,ieng,iong,uang,ueng,uong等等,为后鼻韵,以及两个特殊的普通话/国语变音,也就是两个舌头要卷起来的普通话里的鹅,儿两个音,总共这么六大类读音。
统计下来,在总共4600多个常用汉语字/音里,以 i 结尾的,共有994个,以u结尾的,共有1086个,以aoe结尾的,共有614个,而已n结尾的,有973个,以ng结尾的,共有795个,而以卷舌头的鹅儿发音的,共有147个。这是以普通话/国语发音体系来分辨的。
同样的这些字,在官话发音体系,也就是平水韵+尖团音分流的体系下,同样按照上面的分类原则,但没有卷着舌头发的尾音,同时恢复m闭口音以及入声ktp,则有如下的分布:
以 i 结尾,有826个,以 u 结尾,有929个,以aoe结尾,有316个,以n结尾,有734个,以ng结尾,有800个,以m结尾,有233个,以入声ktp结尾,有781个。
嗯。初步完成了常用汉字的读音标注。算是长久以来想做的一件事,初步做完了。
接下来,就是继续在此基础上,做一些有意思的小研究,和小开发,比如,究竟是入派三声,还是入派四韵?呵呵呵呵
这些都不是正规的音韵学工作,纯粹是民科瞎胡闹。所以还请各位专家学者容忍一二,勿喷哈

有兴趣者可以到下面的网络链接试一试。水平肯定不够,所以有错误,还请勿喷
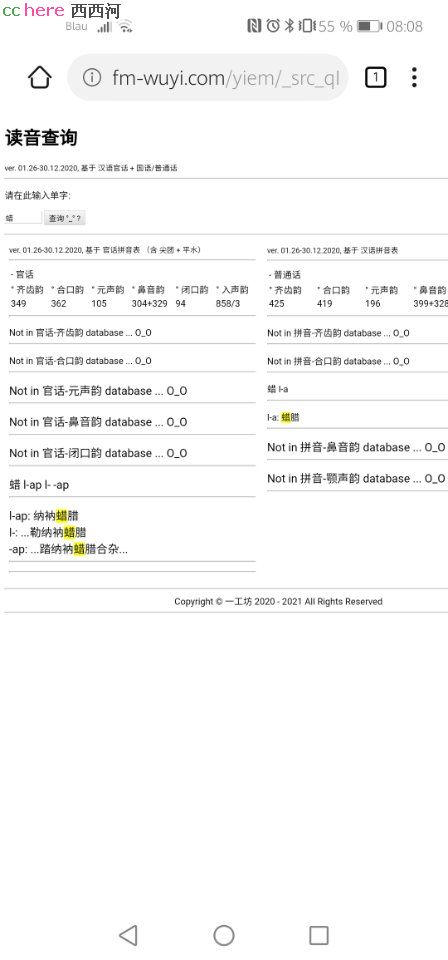
http://fm-wuyi.com/yiem/_src_qPHP/gh_query.html
网址:
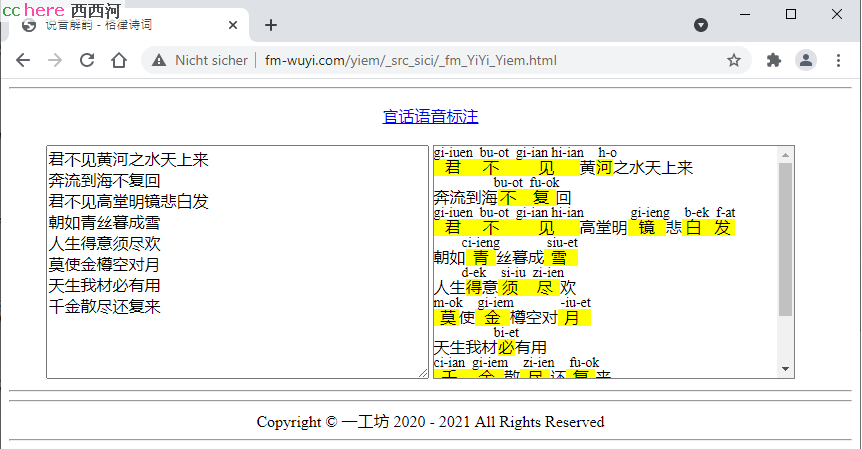
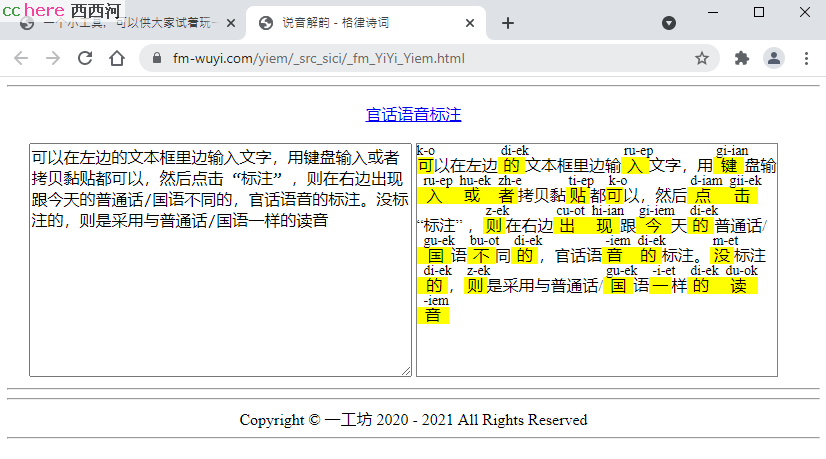
http://fm-wuyi.com/yiem/_src_sici/_fm_YiYi_Yiem.html
可以在左边的文本框里边输入文字,用键盘输入或者拷贝黏贴都可以,然后点击 “标注” ,则在右边出现跟今天的普通话/国语不同的,官话语音的标注。没标注的,则是采用与普通话/国语一样的读音。
不同的读音主要有下面几类:
1,入声音,以ktp结尾;
2,尖团音,以gi,ki,hi,zii,cii,sii开头;
3,闭口音,以m结尾;
4,ong,eng 分离。简单说就是在普通话里 孟 和 蒙 都读同样的音。但在官话里都做两个音,一个是孟,偏向 门 的后鼻音,一个是 蒙 mong,偏向 东 的韵。这一点是根据平水韵而来的。东冬韵与庚青韵是分得很开的。
5,而二尔儿耳等,普通话读er,在官话里读作 ngi,类似于 ni 的音;
6,普通话/国语里的 e 音(鹅讹),在官话里是分在五歌和六麻两个韵里边的。简单地说就是一个读作 o 的音,一个都做 e 的音,后面一个也就是普通话里也夜叶没有 i 的时候的那个音。
嗯,大致也就是上面六个比较在听觉上普通话/国语跟官话不一样的地方。其实 5 和 6 都可以和所谓的元音颚化联系起来,或者可以理解为开口的平舌元音读成卷着舌头的卷舌音。这一点我正在利用语音模拟来验证。过一段时间再跟大家分享结果。
嗯,上面那个小工具的大致效果就如下图:
有兴趣的河友可以去试一试。嗯,水平有限,莫喷哈
顺便提一下,前两天看到有人说,在汉语拼音里,陕西,和山西,如何区分。。。
汗。其实,古人在取这两个省份的名字的时候,会分不清读音吗?当然不会。山,是前鼻韵的an 音;而陕呢,则是闭口音,可以用 sham 来标注发音,也就是读山的时后读出sha。。。后把嘴巴闭起来,就是陕西了。
哈哈哈哈,当然,声调也不一样哈。但是,至少不用什么shannxi这种莫名其妙的拼音方案来拼陕西吧
做好之后,算是基本懂了古典诗词文章里的抑扬顿挫是怎么一回事了,也弄清楚了普通话/国语以及简化字的一些问题。
嗯,算是对长久以来萦绕在脑海里的一些疑惑/问题的一个答案吧。
这个工具至少可以让人一下子就知道,哪些字在古今汉语,和现代不同方言之间会有不同的读音,以及哪里不同。
还在一步步继续推动当中。目的,不在于所谓的对上古,中古,远古的汉语拟音。这些是学术界的任务。在我自己看来,我们目前现在所使用的汉语,原本就有很对不同的读音体系了。再去恢复或者拟构一套或者多套大家都听不懂的所谓古音,跟多出几种汉语新方言,有什么区别呢?或许在学术上有很大的意义。不过在现实中,毫无价值。
我的目的只在于,用最短的路径,让我们能够知道,理解,体会,乃至于欣赏我们的祖先和先辈们流传下来的经典文字里的,抑扬顿挫的音韵起伏和节奏之美。
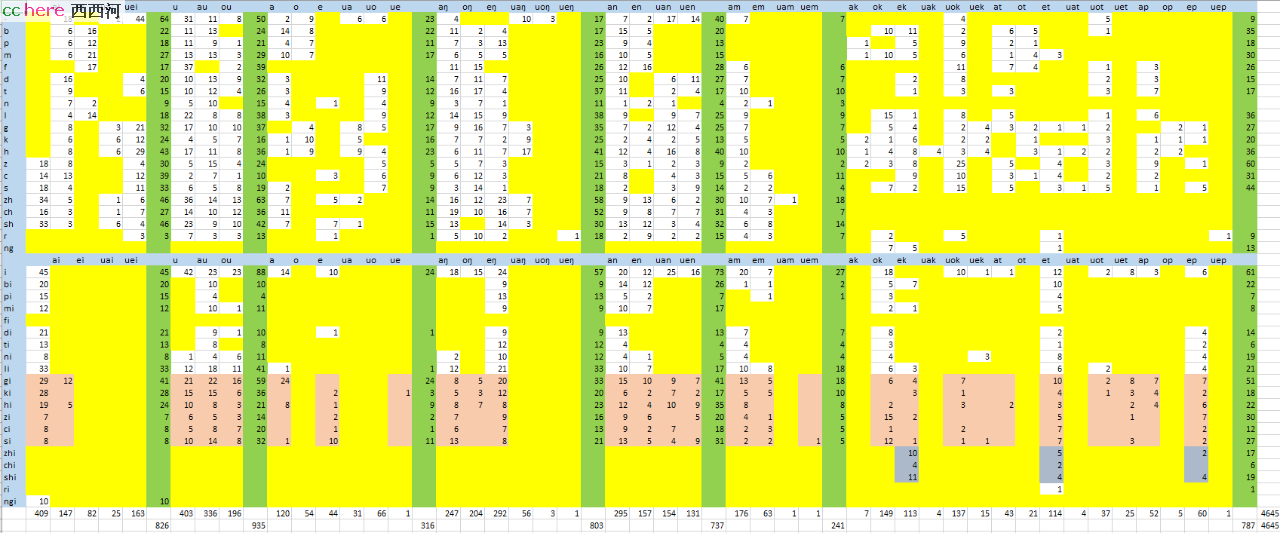
嗯,4645个汉字/音,官话与普通话可以互通的 声/韵 表,每个音各自有多少字/音,都在表里一览无余了。
呵呵呵呵。。。 民科作品,不喜勿喷哦
这么说吧:4600余常用汉字中,
字数最多的读音,为 i,普通话/国语中有 73 个,含官话中的 i 音 45 个,以及 ktp 入声音 28 个。字数次多的读音,为 ji,普通话/国语中有 70 个,含官话中的 gi 音29个,zii 音 7个,gi 入声音13个,zii 开头的入声音21个。换句话说,光是这两个音,在普通话/国语体系下就占据了常用汉字的 3 个百分点。
在官话体系中分离入声之后,字数最多的音有 i (咦) 音45个,uei (喂)音44个,iu (吁)音 42个。换言之,光是这三个音,在官话语音体系下就占据了常用汉字的 2.8%。。。