主题:【原创】园外看花说印刷 -- 河蚌
家园 单就排版本身(不说选字)而言,拉丁文字规则要比汉字复杂 从排版软件设计的难易上可以看出来,汉字每个大小一致,拉丁文字则要复杂许多。
对字体感兴趣的推荐一本书:O'Reilly出版的 Fonts and Encodings
通宝推:蚂蚁不爱搬家,家园 排版上字不一样宽还是很常见的。 西文字母确实是宽度不一致,这个不同于汉字全是一样宽。但是如果只是不一样宽,可以用各种规格的铅块(相当于空格铅字)来填充,还是比较好解决的。
但排版中最怕的是不一样高,就是同一行不同的字型混排,比如“**公司收据”,这里面“收据”是三号字,其它是五号字,排起来就会比较麻烦。
要说排版上的技术高下体现,就在这种地方。
家园 西文排版确实更麻烦 拉丁字母立刻带来了两个问题, 一个问题是kerning, 比如AV, AW相邻, 就要把这两个字母靠得更紧密一些, 例如
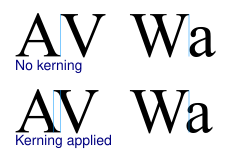 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改另一个是ligature, 相邻两字母如果是ff, fi, 就要连写在一起, 例如
 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改此外, 为美观计, 每行的单词间距分布要均匀, 尽管在不同的行这个间距可以不同. 这里一个关键是对行末断词的处理, 好的断词可以在不影响阅读的情况下, 使每行的单词数分布更均匀, 从而更美观.
大部分英文杂志的排版都做到了以上三点. 严格来说, 前两点是字体特性, 需要字体支持. 最后一点则是排版软件的设计问题.
以前 windows 下的 office word 很难看, 因为这三点都做不到. 再加上 windows 的字体制作和字体优化的原则, 是为了锐利清晰, 而把印刷体斧凿到像素, 所以愈发显得难看. 现在的 word 在open type 字体的支持下, 可以做到前两点, 但也不能自动断词, publisher 才可以, 而 Publisher 这个专业排版组件一般人很少用到, 就连 home & business 的版本都没有, 所以大部分人都直接忽略它了.
绝大部分的英文报纸, 也许为了排版方便, 以上三个美化原则都放弃了, 很多时候都不是左右对齐, 而是左对齐, 这样单词间距也变得更容易处理. 当然报纸文章的宽度较短, 排版难度较大, 也是一个因素.
相比之下, 中文的排版不能不说要简单一些. 你说的字体不同的问题, 因为汉字始终还是方块字, 只要每个汉字在排版上占据的总是一个矩形空间, 处理就要容易一些. 不过, 字母语言的字体设计要比汉字容易得多, 这应该是英文字体比中文字体更加成熟多样的一个重要原因.
家园 排版上西文确实比中文麻烦多了。 即使是字母一样宽也麻烦,得一个字母一个字母的拼,还不用说美观问题。
中文活字印刷的主要问题是,汉字太多了,三千个汉字,上万种活字,拣字及后续处理都很麻烦。
其实这点,打字机表现是最明显的,原来没有计算机之前的机械打字机,英文可是成为日常生活的一部分,连私人信件都用这个,可中文打字机,大家都是听说过没见过,基本上就是一个传说,只有特别正式的公文中才会用到。
家园 小时候在打字室也玩过中文打字机。 说起来以前县以上的单位都配备打字室吧?有一两个专职的打字员,字模都是预先排好了放在字盘上,打字员只要背熟字盘打的速度还是很快的。到八十年代中后期先是四通打字机,再是电脑轻印刷,中文打字机才逐渐被淘汰了。
家园 呵呵,久远的回忆呀 其实我们可以列一下被IT技术淘汰的技术工种,也会发现很多有趣的故事。比如汉字打字员、电话接线员什么的。
ST-2401是最著名的,2401将电脑输入和打印机结合在一起,不过并没有五笔输入法,但即使只用拼音输入已经解决大问题了。
四通在当年就是一个传奇,是中关村的灵魂企业,万润南就是我们的偶象呀。
家园 IBM超级电脑“沃森”一出,马上又有些行业要大变化了 看过IBM美国团队和IBM中国团队的两篇关于沃森研发的访谈,这个沃森突破在两点:
语音识别
智能搜索的算法
IBM打算用在智慧医疗上面,不过看这个沃森的运算扩展性,部分call center的简单没有技术难度的回答也能包办,这样的话又是替代一大堆人工工作了。
家园 Jeopardy里面的Watson完全没有语音识别能力 问题是通过文本形式给Watson的。
Watson强调的是自然语言处理--文本形式的自然语言处理能力。不知道为什么无穷多人都把这个有意无意的误解成语音识别.
家园 IBM当年的语音识别程序就觉得特牛。 我一个同事,普通话比较标准,一直都是将文稿念了变成电子档,可以达到80%以上的识别率。然后再稍微编辑一下就可以,对于不太会打字的人,节省老了时间了。
CALL center我觉得以语音识别替代座席的技术好象并不太实用,因为都是用户直接按键要求人工服务的。除非是明确推出虚拟话务员服务,能够一点不错的回答问题,否则被投述的可能性很大。
倒是IVR那个,真的应该改成语音识别了,什么什么按1,什么什么按2的重复简直让人抓狂。
家园 80%识别率,改起来一样要费老鼻子劲
家园 沃森还是有局限的 1)对“危险边缘”游戏,总正确率是65%。那牛在对答案做置信度分析,选择不回答一些问题。大概有80%的问题覆盖度,对这些问题有85%的正确率。但是,有些场合要求绝大多数的问题都要给出“有用”的答案。
2)在“危险边缘”游戏中,沃森只能给出单一单词作为答案。沃森(或者DeepQA)系统能不能做更复杂的应答,公开的文献没有讲
3)对物理化学这些比较专业,概念间关系很复杂的领域,沃森的概率算法可能不太有效。
当然,沃森被公认是AI的一个革命性进步。
- 复 沃森还是有局限的
家园 举办方为了照顾参赛人员,对IBM沃森做了限制 看过几篇比赛背景资料报道,有可能有遗漏或者偏差,欢迎大家指正:
比赛举办方对IBM沃森做了配置上的限制“
第一IBM沃森是一个几十个CPU的小集群,规模不是很大
第二IBM沃森的数据库是被限制在一个背景数据库资料里面,没有与互联网链接。
就是这样的限制,IBM沃森仍然表现出令人惊讶的学习能力,通过试错迅速矫正自己,从一个首次参赛的电脑迅速成为一个战胜人类选手的冠军,这次比赛我觉得让大家惊讶的就是这种学习的能力和适应环境的速度,要知道其他参赛的人类选手都是身经百战的成熟老手,IBM沃森成长的速度让人振奋吧
如果考虑到IBM一贯的宣传策略,这次新闻报道集中报道IBM中国研究中心的沃森的成果,这也是对IBM中国研究中心团队中的中国研究员也是一个鼓励吧
我想IBM沃森在做简单的比如航班或者时刻表这类问答时候更有优势了,这也是有人猜测IBM沃森这类设备能取代呼叫中心部分简单工作了。
家园 唔,比赛举办方为了照顾沃森,也对题目范围做了限制的 这个在他们自己AI Magazine的文章里说的很清楚。
CPU的限制,并不是关键。沃森现在可以在2秒内完成大多数计算,以及比大多数人类选手快了。更多的CPU,只能加快速度,未必可以提高正确率。
没有与互联网实时互联也不是一个很重要的限制。因为沃森的检索算法需要对网页做语法和自然语言语义的分析,这些不大可能在2秒内在线完成。沃森自己保存了大概2亿页面的数据,基本够用了。
从沃森的论文里,似乎没有提到沃森有学习能力。沃森有一个机器学习模块用来评价各种评分办法的权重,但是这是在参赛前就固化的。
IBM中国研究中心参与了沃森的研究,是很重要的组成部分(特别是和结构化数据相关的模块)。不过,严格来讲,沃森的主力研究队伍还是在美国这边的IBM“沃森”研究中心。这一点,从论文的署名可以看出来。
(好像歪楼了,最好新开个话题)
家园 资料,IBM的访谈 张雷:沃森系统的一个关键步骤是评价备选答案的可靠性。这个可靠性是由上百个算法从各种不同的角度评价得出的。例如:关键字匹配程度、时间关系的匹配程度、地理位置匹配的程度、类型匹配程度等等。沃森在每一个角度上都能得到量化的可靠性评价。而且这些评价算法所依赖的知识源也是可追溯的。所以,如果需要,沃森可以为用户提供答案的依据。
在沃森参赛之前,它会从历史数据中进行学习。比如,如果它回答错了一个往期节目上的问题,它会从中学习到一些信息。在参赛之时,它主要依赖以前学习的结果,但也进行一些简单的在线学习。例如,它可以从已经被其它选手回答的同一类型问题中归纳出一些特点,指导其回答这类问题。另外,答错题目也会导致沃森调整其游戏策略。因此可以说,沃森具备了初步的自我学习和完善的能力。
张雷:非结构化知识主要就是以其原始的文本来表示的,而结构化知识则使用了诸如RDF这样的表示和管理方法。知识出现不一致时,沃森通过对大量往期题目的学习来发现哪些是在该游戏中更值得依赖的知识,而哪些在该游戏场景中是不可靠的。
张雷:对于人工智能实践来说,沃森的经验表明依靠单一或少数算法是很难成功的。而依靠大量的各种小算法的集成更容易取得进展。这似乎和生物界的多样性有着相似性。另外,沃森也说明,人工智能技术已经取得了相当大的进展,通过大规模的集成这些技术,很多我们看似很难的问题已经从“不可能解决”变为“可能可以解决”。例如,沃森表明,以前人工智能中的知识获取的瓶颈(knowledge acquisition bottleneck)似乎变成了一个可能可以解决的问题。
对人工智能的担忧在现阶段是没有必要的。我们还没有看到机器具有自我意识。所有的功能都是由人控制和提供的。在现阶段,人工智能技术,包括沃森,是用来帮助人的,而不是取代人的。
张雷:沃森代表的是自然语言处理和人工智能技术的突破,可以应用于很多领域,例如医疗、金融、电信、政府服务等。例如,在医疗领域,医疗记录、文本、杂志和研究资料都以自然语言编写——这是一种传统计算机难以理解的语言。一个可以立即从这些文件中找出准确答案的系统能够给医疗行业带来巨大的改变。IBM最近宣布与Nuance通信公司签署协议,在医疗行业探索、开发沃森计算系统的先进分析能力,并实现其商业化。当然,为了让沃森真正服务于这些领域,可能还需要准备相应的专业知识库等额外的努力。沃森不是万能的,对于具有很大主观性或依赖个人生活经验的问题,沃森现在是不擅长回答的。
张雷:沃森确实是一个庞大的系统。但具体来说,也就是运行在不到100台的IBM Power7服务器上。因此,它也并不是可望而不可及的。很多企业和机构已经拥有远不止100台服务器。当然,要让沃森服务越来越多数量的问答请求,需要的机器数量会上升。因此,我们也不排除通过云服务的方式来提供沃森。
张雷:IBM中国研究院在研发沃森系统的过程中,发挥了重要的作用。我们为沃森系统采集、分析和使用各种结构化的知识,利用结构化和高可靠的知识提供问题解答,排除让系统显得“愚蠢”的答案,以及帮助沃森系统提高其学习能力。来自IBM中国研究院的很多技术成果已经融入在沃森系统中,而有的研究成果则为整个科研团队提供借鉴和参考。
不久前,IBM超级计算机沃森(Watson)在美国电视智力答题节目《危险边缘(Jeopardy!)》中上演了人机大战,并最终击败两位人类冠军,赢得最后的胜利。沃森由IBM全球多个研究院和大学共同研发,历经四年研制而成。IBM中国研究院也参与了该项目的研发。InfoQ中文站有幸采访到来自IBM中国研究院直接参与了沃森项目的张雷博士。张雷博士是IBM中国研究院信息与知识管理部门研究员,在过去的三年中,他和他的研究团队与全球研究团队一起,致力于深度问答项目(DeepQA)的工作,研究并开发了沃森系统。在IBM期间他申请过多项专利并获得过IBM杰出技术成就奖。在学术领域,张雷博士研究兴趣广泛,涉及语义Web、知识表示与推理、信息抽取与检索、问题回答系统以及机器学习等,发表学术论文20余篇。他是WWW、IJCAI、ISWC等重要国际学术会议的程序委员会委员、第九届国际语义网大会(ISWC2010)的本地组织者之一,还是第一届中国语义万维网论坛(CSWS2007)的主要发起人之一。下面有请张博士为我们揭开沃森背后的技术奥秘。
http://www.infoq.com/cn/articles/ibm-watson-ai
家园 貌似新浪也是从四通利方演化过来的