主题:【原创】科学的欣赏流行乐 -- 比的原理
正是自己有兴趣的文章。
[FLASH]http://player.youku.com/player.php/sid/XNjg5MTM1NjY4/v.swf[/FLASH]
http://v.youku.com/v_show/id_XNjg5MTM1NjY4.html
1. 男女声音的本质不同:音高不同
这是废话,地球人都知道。都说女声比男声高八度,其实不能,高4-6度差不多。
2. 男女声音的不同:亮度
从直观上这个很好理解,女声普遍更“亮”,“尖”。穿透力更强。这是由于高频泛音丰富导致的。也就是我们通俗的说法“头腔共鸣更强”。视频里面已经解释的非常清楚了,上一下图:
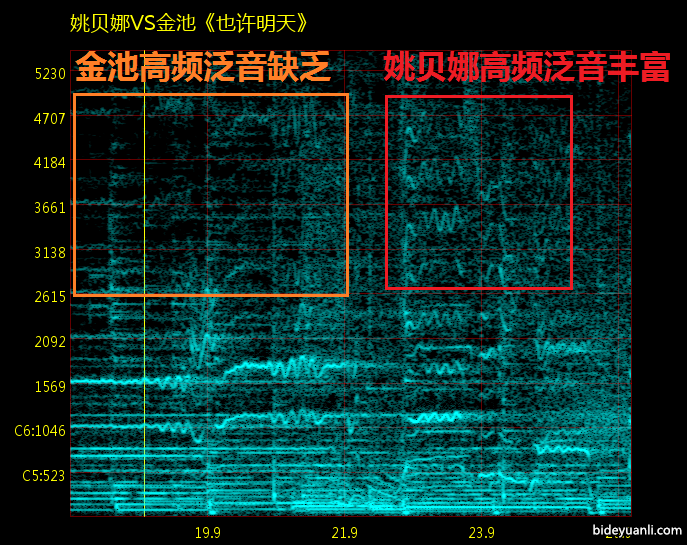
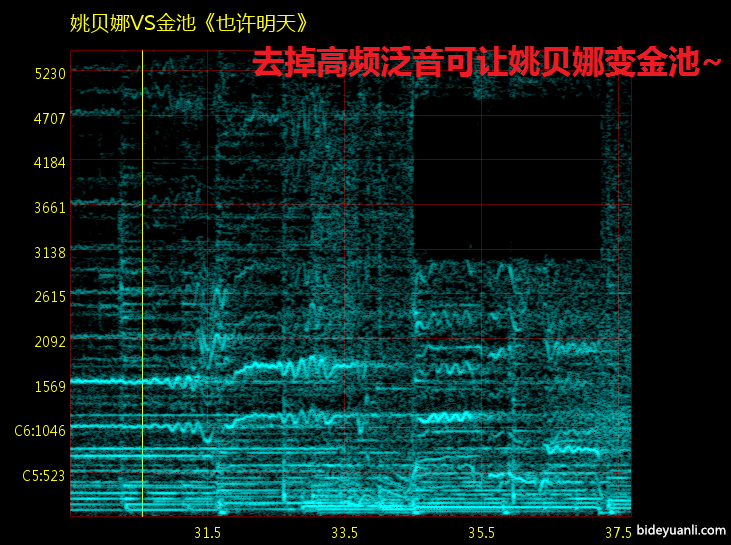
注:头腔共鸣和高频泛音,学术界有不同看法,见http://bideyuanli.com/p/780里关于歌手共振峰的段落。
3. 男女声音的不同:糙度
即使我不讲这个词,相信绝大多数人也能非常直观的理解“糙度”:男声就是比女声糙嘛。
然而与大家想象的不同,并不是说男声就比女声“宽”一些,或者说“毛刺”多一些之类的,实质上这是一个听觉问题。
人耳的听觉事实上问题挺大。。。当两个振幅差不多,频率接近的声音出现时,人耳会无法区分这两个声音。进而判定他们是一个声音,只不过比较“糙”。
上面一句其实包含了两个要素:
1. 振幅差不多。如果振幅差的比较多,那一个会掩盖另一个(掩蔽效应)。
2. 频率差不多。多少算是差不多?这是一个复杂的问题,取决于频率,也取决于振幅差。一般来说1/10频率是大概估测。也就是说,1000hz 和1100hz的声音是差不多的。小于这个值也是可以的,当然糙度会下降,比如1000hz 和1020hz合成之后的糙度就不如前面那个合成。
视频中的例子:用两个振幅一样,频率接近的声音去制造糙度。
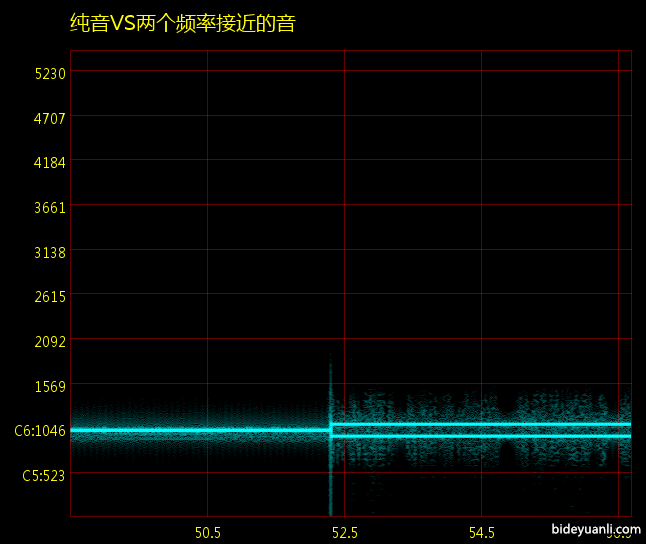
有了这个结论,男女不同就很容易解释了:男声天声低,泛音之间的间距更小,自然就更“糙”。
总的来说,糙度还是直接取决于音高,音高比较低的自然就更糙。这也很好的解释了为何女声天生音低就自然的像男声了。
我们看看视频中的例子:
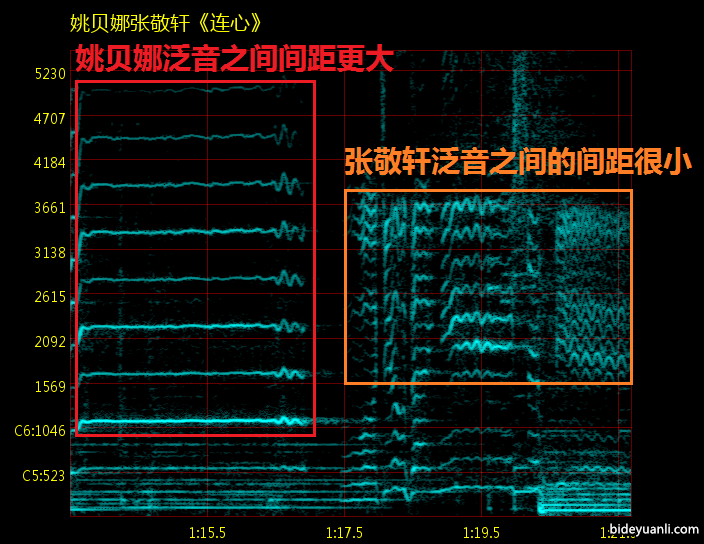
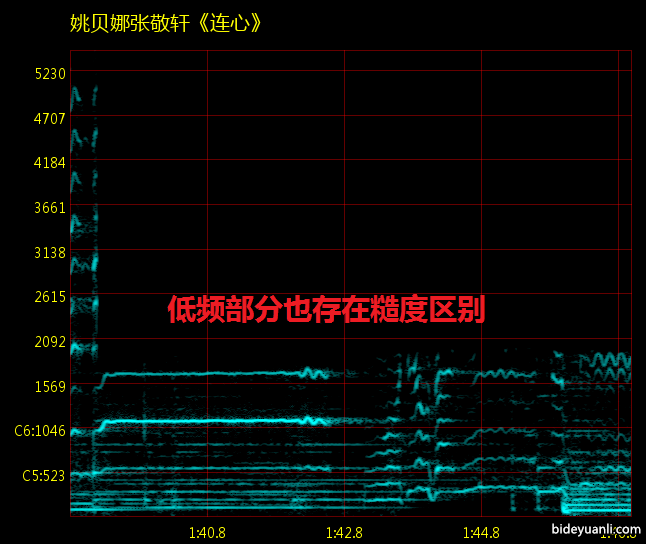
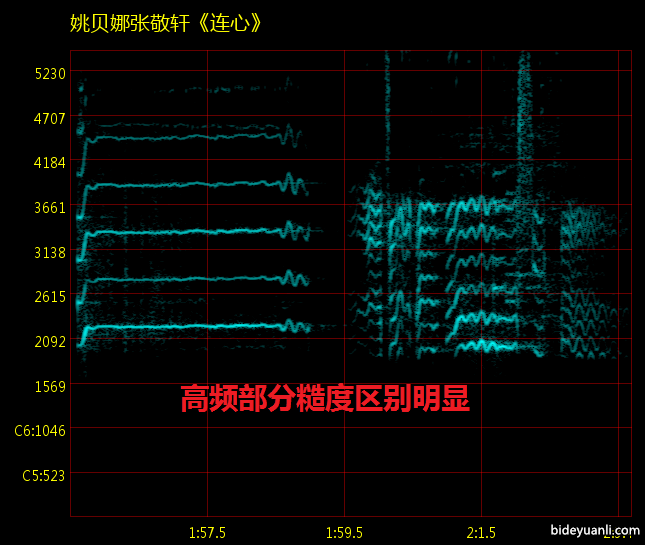
张敬轩的基本功其实相当好,高位置共鸣明显。这在现在的流行乐坛可太罕见了。这就是为什么他音色好听的原因。(当然他比较倒霉,遭遇了传说中的巅峰姚,直接在声压上被秒成了翔)
同样是高频丰富的姚贝娜张敬轩,我们依然很容易的辨认出张敬轩是男声,就是因为他高频泛音之间的间距非常小,糙度很大。
4.如果男声音高,同时头腔共鸣强烈,怎么办?
几乎没法分辨。。
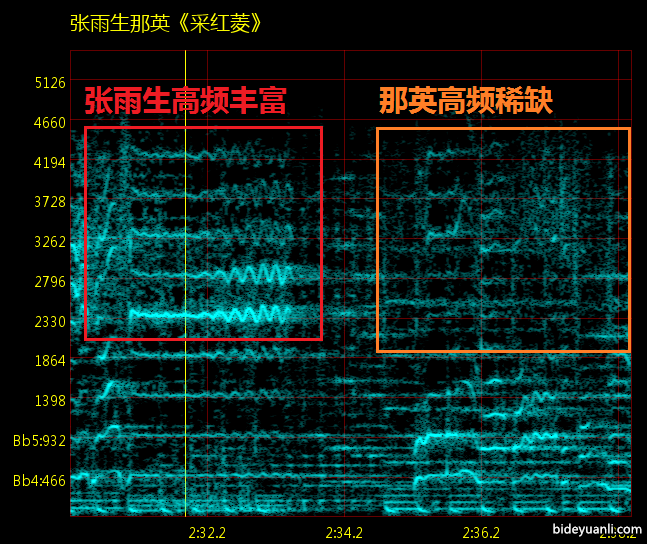
这个我真不是黑那英,那英整首基本都这个共鸣水平,被宝哥爆的一地翔。
(视频地址:http://v.youku.com/v_show/id_XMzc1NDY2ODA=.html)
这时候我们只能看力度,也就是气息共鸣水平。男声一般气息比女声强一个数量级,所以共鸣水平要高得多。比如之前我放过很多次的阿妹哈林《我期待》,就是典型的哈林力度完爆阿妹。
这个时候,往往出现与第二条相反的局面:就是男声一般高频比女声强。
当然,实实在在能唱到女声音部的男声比较少。
题外话:为什么张新就是个娘嗓,赵晗就是个爷们呢?因为张新力度太弱了,同唱一个key,张新几乎无力度,他那个才是真没法区分男女。他只有唱到非常高的音区才能有力度,这就是典型的音域断层。
声带
从声带本质来说,儿童声带是短而薄的,变声之后声带变厚,同时男的变长很多。
所以
童嗓是短而薄
女嗓是短而厚
男嗓是长而厚
当然男嗓比女嗓声带还是厚一点。
据我目测,张雨生的声带是长而薄,所以是童嗓。
其实童嗓比较无敌,比如这个:
http://v.yinyuetai.com/video/3229
当然大部分儿童气息不够,一旦气息够了的就很无敌了。
本帖一共被 1 帖 引用 (帖内工具实现)
有名的初音未来就是vocaloid系列中的一员,但她并不是该系列第一个人声软件,她只是最先以拟人形象走红的。
VOCALOID系列成员角色如下,其中有一位字体加粗的角色为中文发音软件,同样出自V家系列。(以下内容引用网络资料)
LEON(英语、男声,ZERO-G)
LOLA(英语、女声,ZERO-G)
LEON和LOLA同为VOCALOID最初的产品。
MIRIAM(英语、女声,ZERO-G)
MEIKO(日语、女声,CRYPTON)
日语第一套VOCALOID的产品,擅长流行曲、摇滚乐、爵士乐、R&B、童谣等广范围歌种[3]。由拜乡芽衣子(拝郷メイコ,拜乡芽衣子)提供原声[4]
。
KAITO(日语、男声,CRYPTON)
清凉感声线,擅长歌谣曲、童谣。由风雅なおと提供原声。
VOCALOID2系列角色
角色主唱系列(日语,CRYPTON)
CV01 初音未来(初音ミク, 初音未来),女声,由藤田咲提供原声。
初音未来初发售时则爆发热潮,并出现音乐软件罕有的高销售数。
CV02 镜音铃、连(镜音リンレン, 镜音铃、连),男女声,由下田麻美提供原声。
CV03 巡音露卡 (巡音ルカ MEGURINE LUKA),女声,CV:浅川 悠 2009年1月30日发售
SWEET ANN(英语、女声,POWER FX)
瑞士人提供原声。
Big-AL(预定发售,英语、男声,POWER FX)
PRIMA(英语、女声,ZERO-G)
由英语系的歌手提供原声。
SONIKA(英语、女声,ZERO-G)
由英语系的歌手提供原声。
GACKPOID Gakupo(がくっぽいど)(日语、男声,INTERNET) 由日本歌手Gackt提供原声。
Megpoid Gumi(メグッポイド)(日语、女声,INTERNET) 由日本声优中岛爱提供原声。
小学生「歌爱ユキ」
老师「冰山キヨテル」
SF-A2 开発コード miki」
猫村いろは (猫村伊吕波)(日语,女声,AH-Software)
VOCALOID3系列角色
Megpoid Gumi Append,女声,日语,英文,由中岛爱提供原声
CUL,女声,日语,由喜多村英梨提供原声
Lily,女声,日语,由yuri from m.o.v.e提供原声
Gackpoid Append,男声,日语,由GACKT提供原声
Galaco(私人vocaloid不发售),女声,日语,由柴咲幸提供原声
VOCALOID软件
Mew,女声,日语,由坂本美雨提供原声
VY1,女声,日语,原声提供者未知
VY2,男声,日语,原声提供者未知
兔眠りおん,女声,日语,原声提供者未知
结月ゆかり,女声,日语,原声提供者未知
苍姫ラピス,女声,日语,由江口菜子提供原声
IA,女声,日语,由Lia提供原声
Mayu,女声,日语,由森永真由美提供原声
KAITO Append,男声,日语,英文,由风雅直人提供原声
初音ミク,女声,日语,英文,由藤田咲提供原声
Oliver,男声,英文,原声提供者未知
AVANNA,女声,英文,原声提供者未知
SeeU,女声,韩文,日文,英文,由Kim Dahee提供原声
BRUNO,男声,西班牙文,原声提供者未知
CLARA,女声,西班牙文,原声提供者未知
洛天依,女声,中文,日文,由山新提供原声
AKIKO LOID CHAN(私人广播vocaloid不发售),女声,日文,由有本提供原声
vocaloid3开发冻结中【暂】
リングスズネ(ring),女声,ヒビキルイ(lui),男声
红楼梦插曲里面,我指的是女声,比如片头曲、葬花吟、秋风秋雨歌之类的那些,听上去既象戏又象歌,那是什么唱法的。
没看过红楼梦,搜了一个
https://www.youtube.com/watch?v=2HZDu-u7KNU
从这首来看,偏戏曲吧。
其实戏曲作为无麦时代产物,只有一个特征,就是一定要求高位置共鸣,并且吐字清晰,并没有其他特殊的要求。所以戏曲也有那么多流派呢。
从这个角度来说,现代歌唱家,尤其是民族歌唱家,唱法像戏曲一点也不奇怪,本来就差不多。所以我写到三种唱法的时候没提戏曲呢。
应该说,唱法上没太大区别,只有配器曲风唱腔上的差别。
从发声原理上来说,声音大体可以分为两类:
1. 物体振动发声。通常就是固体振动,这个很容易理解,就是固体振动带动空气振动产生声波。
2. 空气振动发声。
关于空气振动发声,我们都知道声波就是空气在介质中规律性振动。其实就是这样:

所以,只要空气产生振动就可以产生声波,并不一定要固体振动来带动。有了这个基本思想,我们就可以知道,空气自身就可以产生声音,只要有扰动。
所谓的边缘音(edge tones),就是气流经过固体边缘,发出声音。边缘音是最典型的空气振动发声。
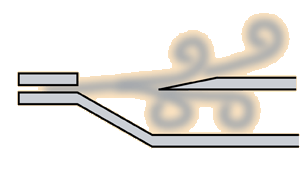
如图所示,气流吹向一个固体边缘的时候,自然分成两边,产生了气流漩涡,空气振动就发声了。最典型例子:笛子。
我经常举得例子:拿个刀片挥来挥去,发出的“嗡嗡”声,就是边缘音。相对的,用手指去弹刀片,发出的“叮叮”声就是固体振动发声。
事实上,空气扰动发声的形式有很多种,比如这样:
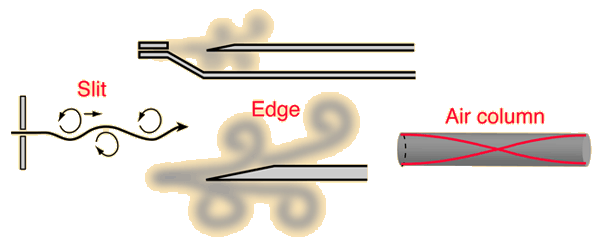
气流经过裂缝;气流经过边缘;气流在空管内震荡;等等。
也有人叫空气和物体摩擦发声,我觉得“摩擦”一词不准确。
更多例子:
1. 喘气声,呼气声。唱歌中的气声。
2. 对着瓶口吹气。
3. 口哨。
4. 笛子。
5. 风声。
6. 齿音。就是用舌尖顶住上门牙,让气流经过牙齿发声。就是上面讲的裂缝音。hifi界的齿音扩大到大部分口腔内制造的边缘音。
边缘音特点:一般没有固定基频,即没有音高。(除了笛子等有共鸣腔辅助的)
(笛子为什么特殊?因为有个共鸣腔阿,实质上你要是把笛子吹孔那一小段锯下来,对着孔吹也是没有音高的。当然了,这样也没多大声,没共鸣就没音量嘛。)
相对的,固体振动发声一般都有音高。
这很显然,因为空气的振动是很不稳定的,当然不会有音高。声音是散布在一个很大的频率区间内。如下图
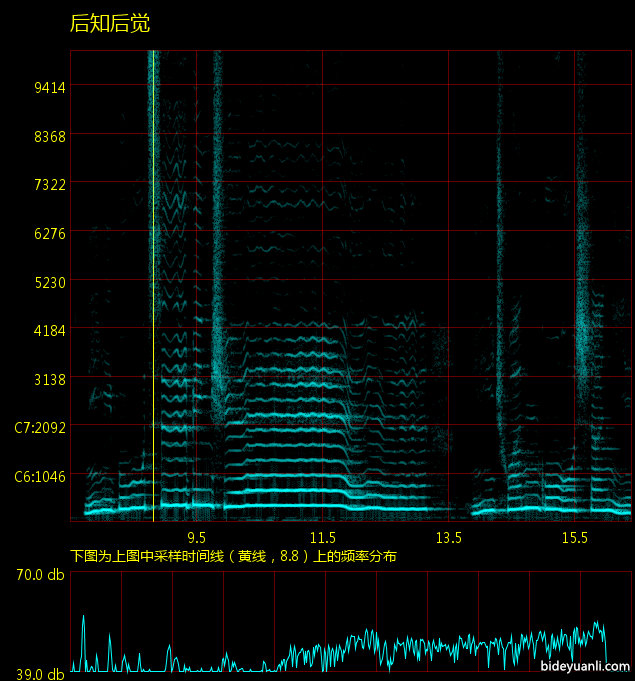
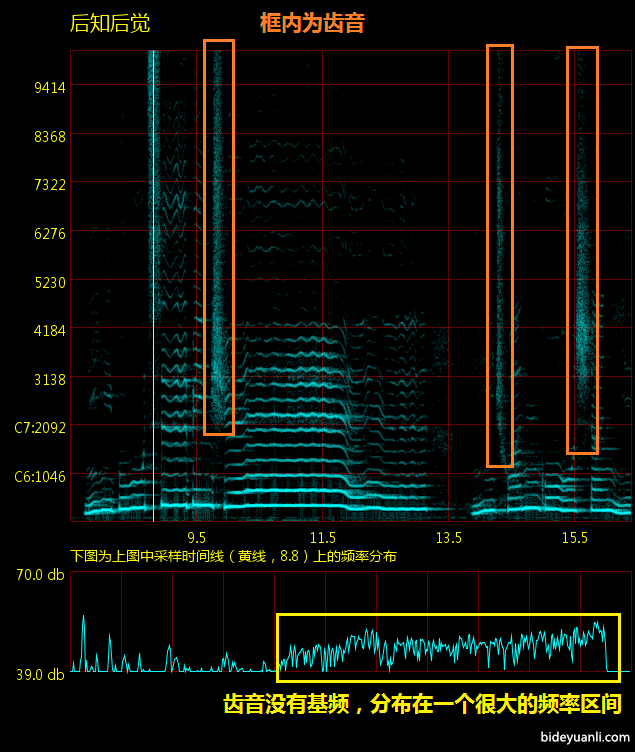
对比很明显,齿音是一大片雾状物,而正常的声音是一条条线,也就是基频/第一泛音/第二泛音/。。。这样的叠加。
从这点上讲,对耳机等设备来说,边缘音就比较难以还原。因为我们都知道耳机是靠固体振动(振膜)发声的,用固体振动去模拟空气振动?注定了会比较麻烦。
齿音对耳机产生困扰的另一个原因是:耳机是没有距离感的。我们都知道现实世界中齿音音量极小,随着距离的提升迅速消失,不要说离的很远,就是面对面说话,齿音一般也很难听清。但是对耳机来说,相当于是要还原一个耳朵贴在演唱者嘴的声场,所以齿音就显得过于明显。
英文资料:http://bideyuanli.com/wp-content/themes/edge/edge.html
本帖一共被 1 帖 引用 (帖内工具实现)
泛音其实是固体固有的振动特性通过带动空气振动产生的,
那么液体呢,液体是不是也和空气一样,都是流体所以没有泛音?
固体振动产生固定频率(基频/第一泛音/第二泛音/等等)是因为只有那些频率的声音才能在固体内形成驻波
也就是说,固体相撞,产生了无数频率的声音,但是只有这些频率的声音延续了下去,其他频率几乎是一瞬间就消散了。
所以只要可以形成驻波,就可以产生音高。空气振动一样可以,比如笛子,有共鸣腔就可以产生音高,也有那些泛音。比如灌水壶,声音是不断升高的。
所以液体也可以,比如一排一样的杯子盛着不同量的水,我们都知道敲击这些杯子可以奏乐。这就是因为水形成了一个可以产生驻波的共鸣腔。
准确的说应该是有一个固定的空间,比如一个圆型烧瓶也行。
也不能绝对,总有些例外。
自古说“曲高和寡”,您的这个帖子,感觉受众范围太小,因为几乎纯技术了。但是还是很佩服楼主的专业精神。
给点建议,楼主不妨以谈音乐,歌曲欣赏为主,夹杂点原理,技术内容,用例子讲讲原理,技术对音乐,歌曲的创作,表演的得失。这样既看的人多了,发表观点的也多了,您还科普了大家。感觉现在正好反过来,大家感兴趣的是某些您对提问者的回复,而对主贴大家却都大多云里雾里。
比如百家讲坛,就可以把学术变成面对老百姓的电视节目,而且还很红。
呵呵,一孔之见,见笑方家